






























































Totems of daily splendor - where is my side; II
The project can be considered as an interactive self-portrait which functions as a bridge in between different temporal conditions; namely: the past, present and future. This “machine “can be also used by the audience as a generator of non-linear audiovisual stories.
Eleni Alexandri
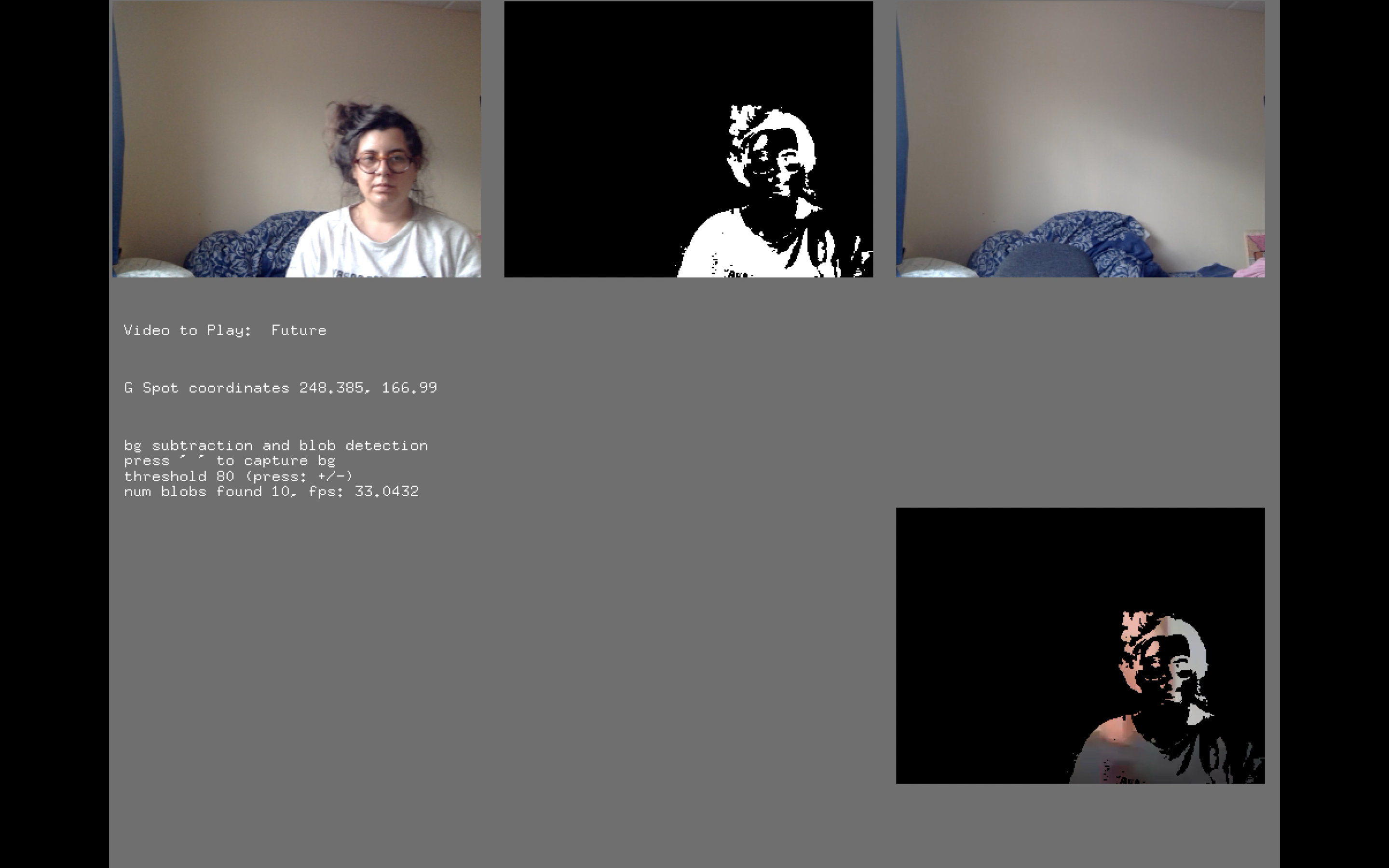
Back in 2011, I started the series “Totem of daily splendor” an ongoing project of video notes which present my perception of daily banality commenting on the relationship of the self with the physical and social environment. Although we tend to deal with the daily small things rather superficially, they could provide us with a picture of innermost self of being. This section of “Totems of daily splendor” series explores and comments on the vague concept of time. The time as an unstable, weirdly countable and determined term; usually classified in the three main categories of the past, present and future. The borders of past and present are vague, but The Future seems as another state of time from the current present (+-), full of potentiality. I have chosen videos of my personal archive to represent these three conditions of the time in my piece. For ”the past” I use footage from the first years of my adult life, while the present is represented by video footage from current period and more specifically from my life in London. Finally, the future is not just a displayed video activated by the position of the audience, it makes a dialectic with the audience by masking their own figures into a video which represent transgression as a promise of the future’s potentialities.
video-notes from the series “Totem of daily splendor”
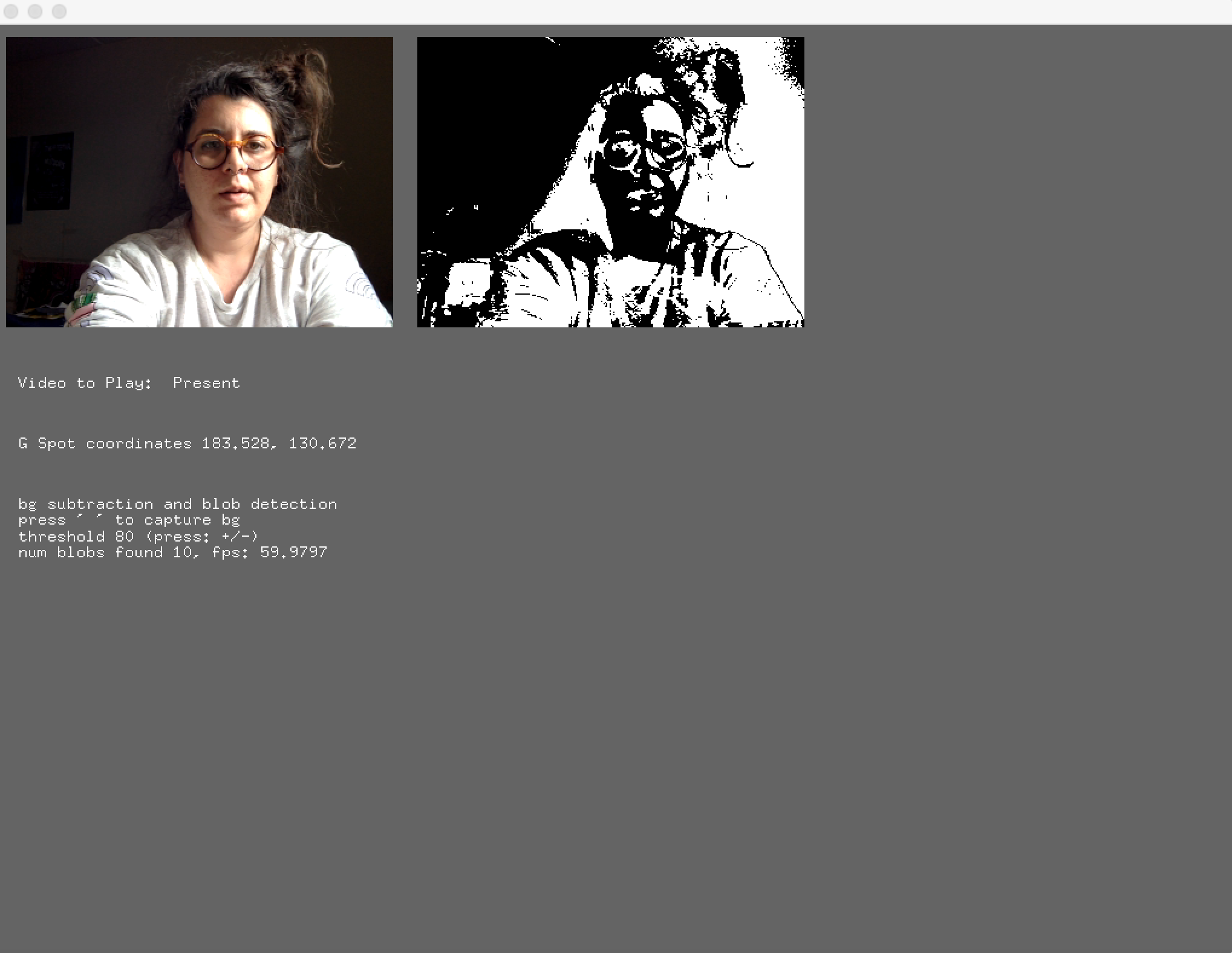
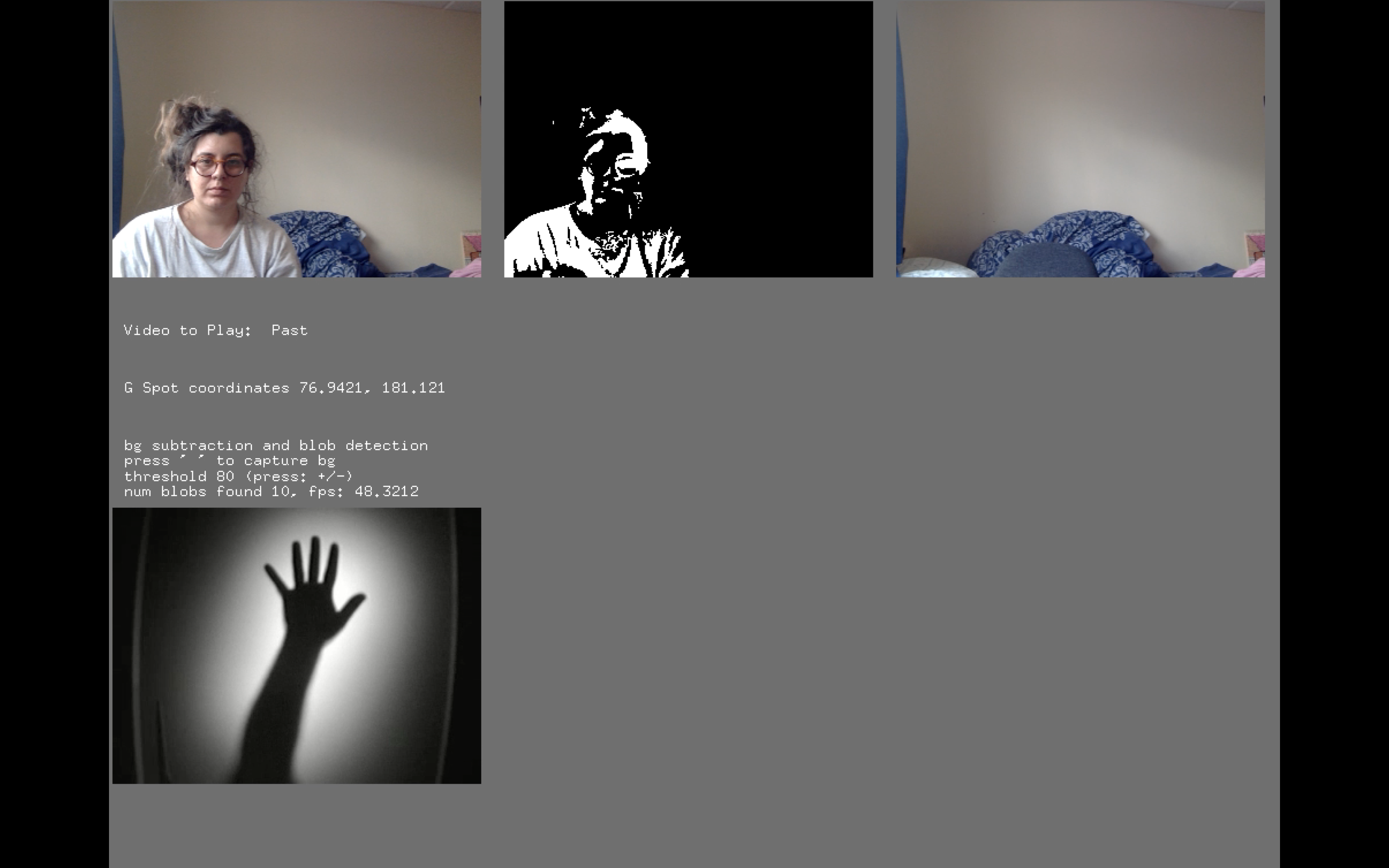
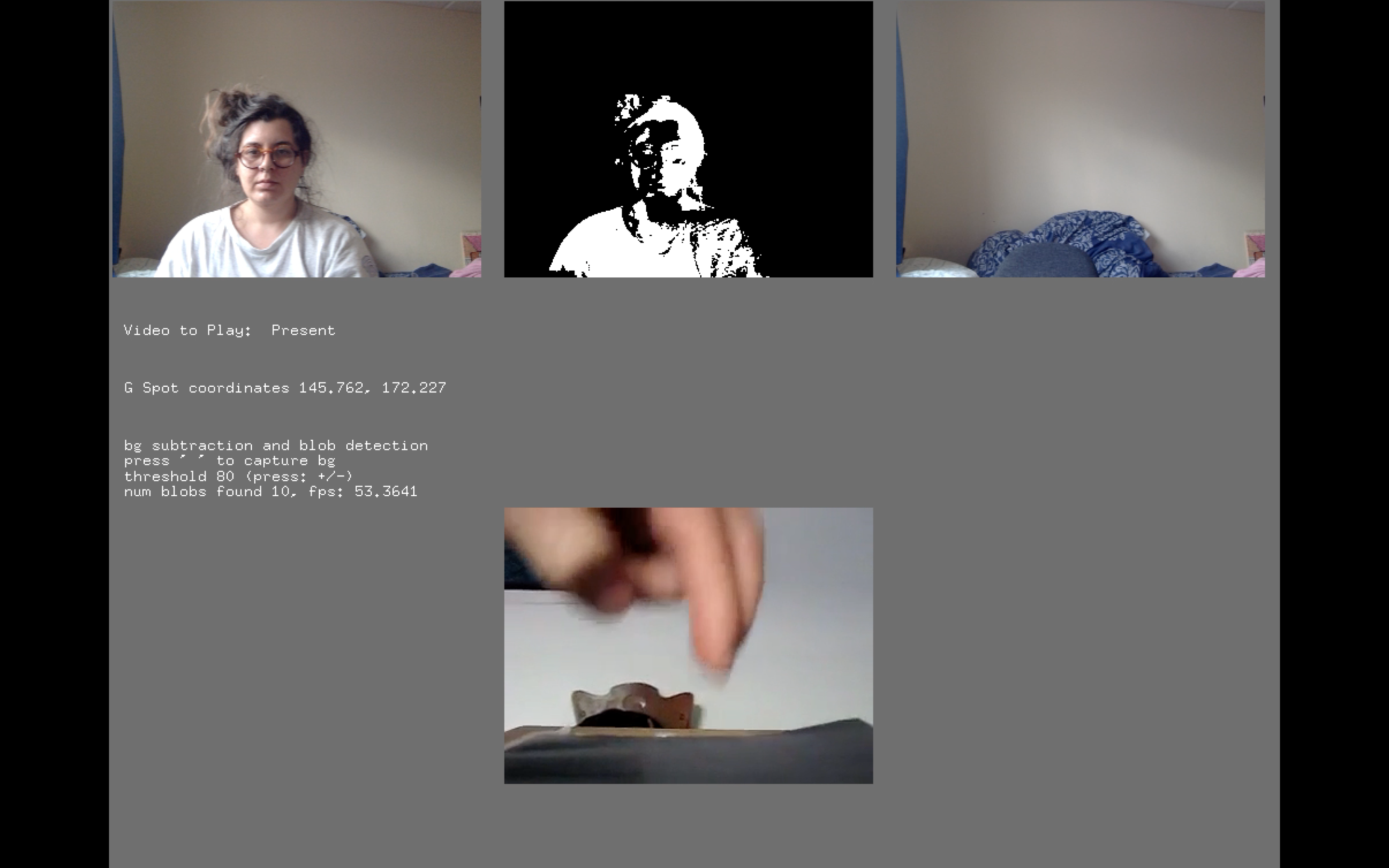
Interactive video projection “totems of daily splendor where is my side; II” works as bodily navigator of a screen. The individual who interacts with the piece should move into space so as to reveal different parts of it. More specifically, a video camera exists in the centre of the upside of the display surface; this camera gives the coordinates of people in its optical field to the program so as to play the related video. For instance, If the audience stand or move in the first third of the screen a random video of the determined "past condition" will appear on the screen, similarly, if they stand/move in front of the second third of the screen a video for "the present", while the final third is related to "future condition" which masked the figure of the audience in the displayed video; audience can move into the space to reveal different parts of the image. Every time that the audience chance condition with them position the machine chooses a new random video to display from the related condition.
For the creation of the piece, I used an audio-visual editing software in order to do the montage of the footage of my personal archive while the interactive part is programmed in open frameworks/C++ with computer vision input using OpenCV addon. I start my approach from the OpenCV example, which detects blobs depend on their movement and their difference from the background. The background defined as the first captured image of the camera few seconds after the application starts with a counter. Furthermore, I separate my screen into three equal parts and by finding the centre of blobs summaries (audience figures’ centroids) I determined in my code which video will play depends on audience position in the area in front of the screen. Lastly, for the part of the future, I created a mask for audience figure by sorting the blobs summary and I passed the visual information of the video into them so that, the figure/blob can be actually displayed inside their threshold.
I would like to further develop my application so as to have more activation points and receive input data from the roof cam.
References:
Openframeworks
ofxOpenCV