






























































Museum of Borderlands
Museum of Borderlands is an interactive sound installation that explores algorithmic decision-making in physical space.
produced by: Veera Jussila
Introduction
The installation takes the form of an iterative museum that seeks to map our current fears. It invites us to explore what becomes labelled as a threat and what kind of new connections are born when images are increasingly grouped by their similar form in machine vision.
Concept and background research
After experimenting with GANs and notebooks during my machine learning module, I wanted to explore a new direction with computer vision and interactive classifications for my final project. This was inspired by a book Sorting Things Out (Bowker and Star 1999) that investigates the hidden power classification systems hold in society. Furthermore, I was interested in the double role of monsters in artificial intelligence: AI is both seen as a monster and increasingly used to detect monsters, ie. to recognize deviant behaviour that doesn’t fit into desired categories (Dove and Fayard 2020).
Drawing from Haraway’s The Promises of Monsters (1992), I set out to explore monsters as something yet-to-be that challenges the categories of our worldview. Instead of vampires and werewolves, I was interested in invisible, abstract monsters (Weinstock 2017) as the real source of uneasiness today. Of the many possibilities I chose to focus on viruses and surveillance. My machine learning practice was strongly inspired by what McQuillan (2017) calls for as a counterculture in data science and what Brain (2017) refers to as eccentric engineering. By using a small, hand-picked dataset, exposing it and inviting audience to contribute, I strove to make the deep learning process transparent and more democratic. Small, subjective datasets are a direction that Anna Ridler (2020) and Hannah Davis (2020) have explored in their practice as well. Similarly, Sebastian Schmieg (2016) has invited the audience to classify the image collection on The Photographer’s Gallery’s website.
When it comes to computational installations, Goldsmiths alumni Laura Dekker (2017) has previously investigated real-time classifications where audience provides materials for the machine to see. However, whereas her piece emphasized machine as an autonomous agent, my project set out to explore collective knowledge-making and human-computer interaction.
Finally, I was studying a fair amount of archive theories, mainly from the sources listed by professor Shannon Mattern (2020) in her extensive teaching database for The New School. I was, for example, inspired by image classification initiatives by librarians Bernard Karpel and Romana Javitz that were based on affinities and images as documents (Kamin 2017). When I was later browsing virus images by Wellcome collection, I was intrigued to see that the recommendation system offered me "visually similar" images based on patterns and edges without a related context – a Karpelian machine vision model in full action. The consequences of this new kind of pixel-based groupings became one of my central questions.
I chose to have a museum as a framework for my installation. Organizing information into categories is an essential part of how museums work. Many of them strive to decolonize their old classification systems (Shoeberger 2020). Simultaneously, some museums strive for audience engagement via Instagram-friendly colors and contemporary designs. A pastel-colored, friendly and not-too-original design was something I was after in my prototyping.




Technical
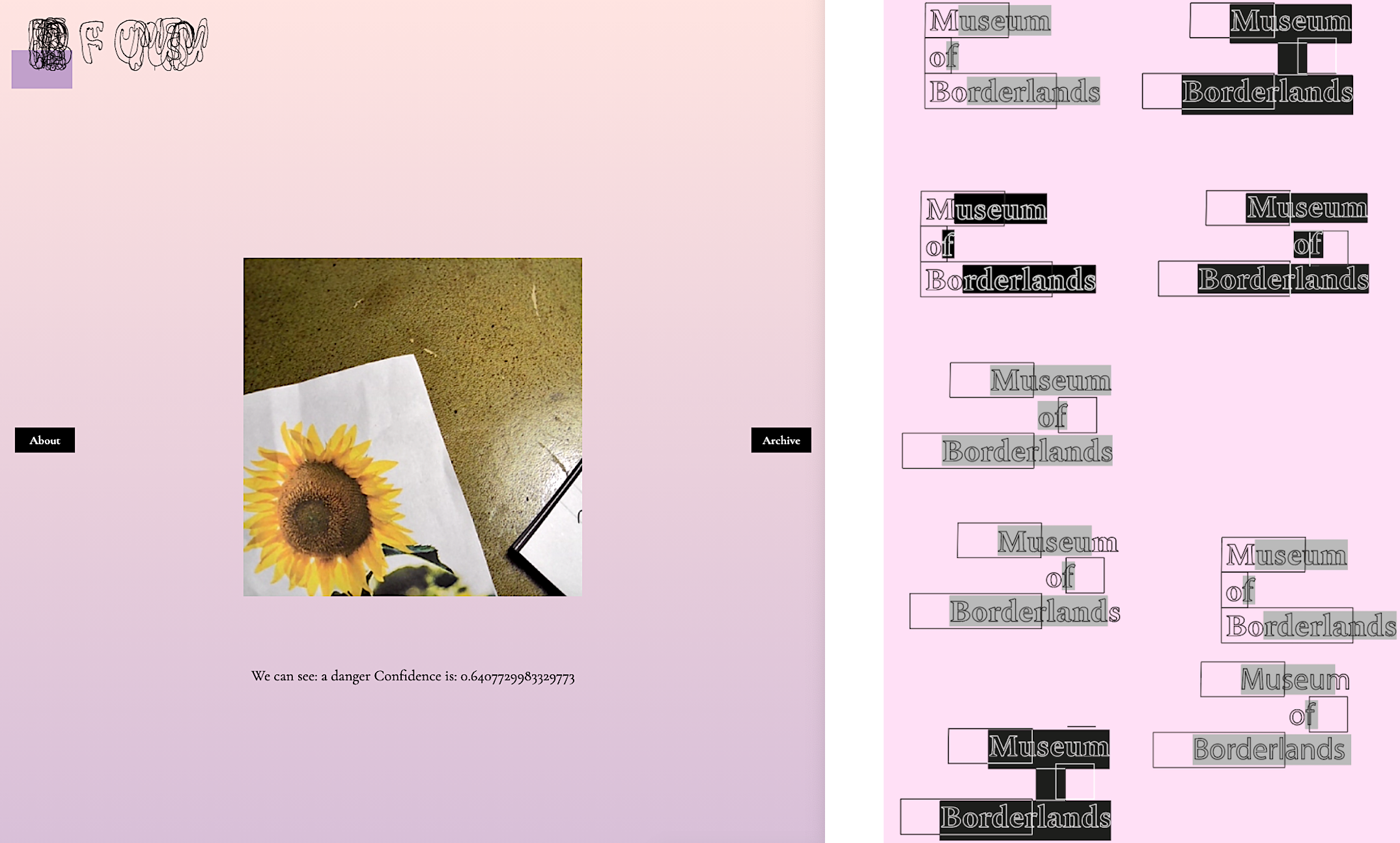
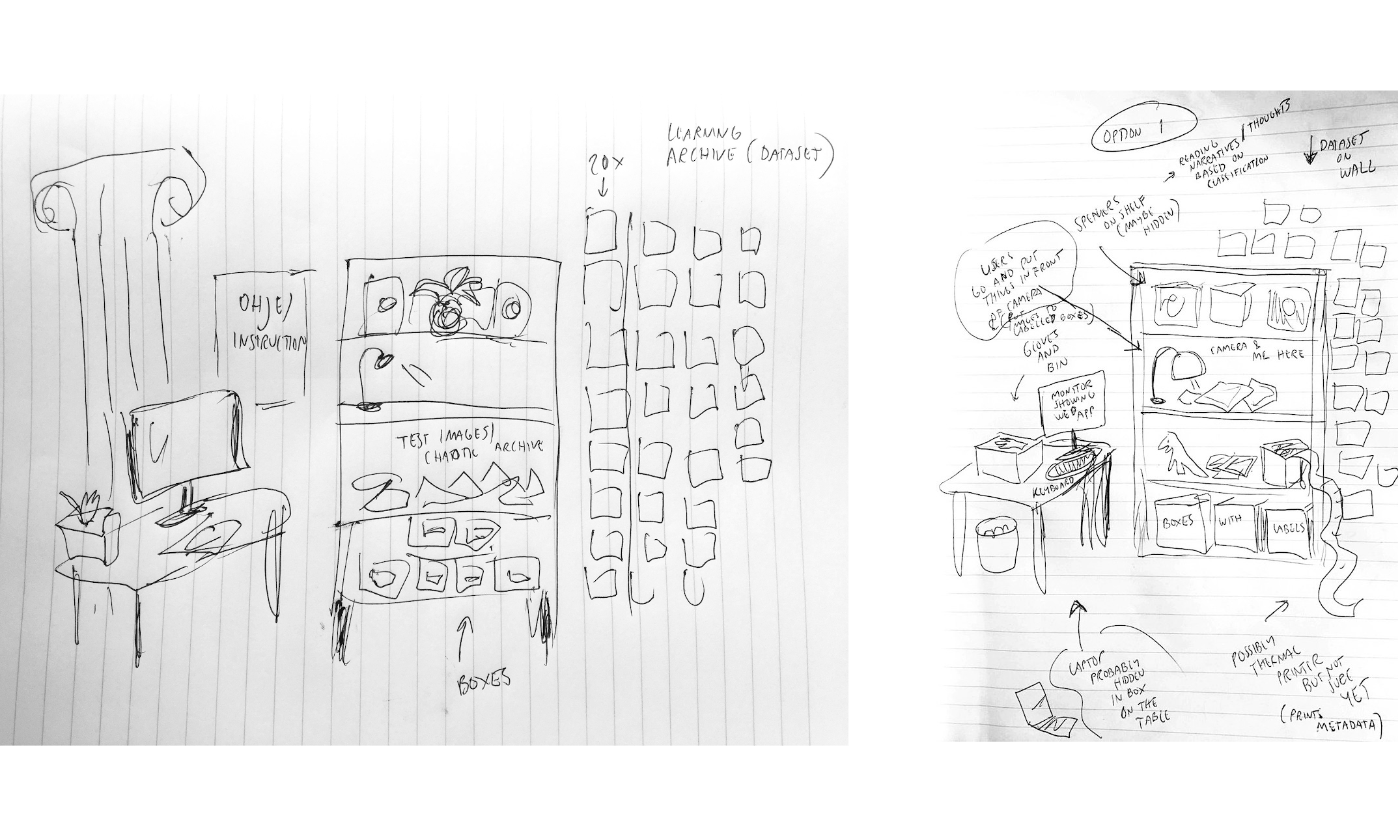
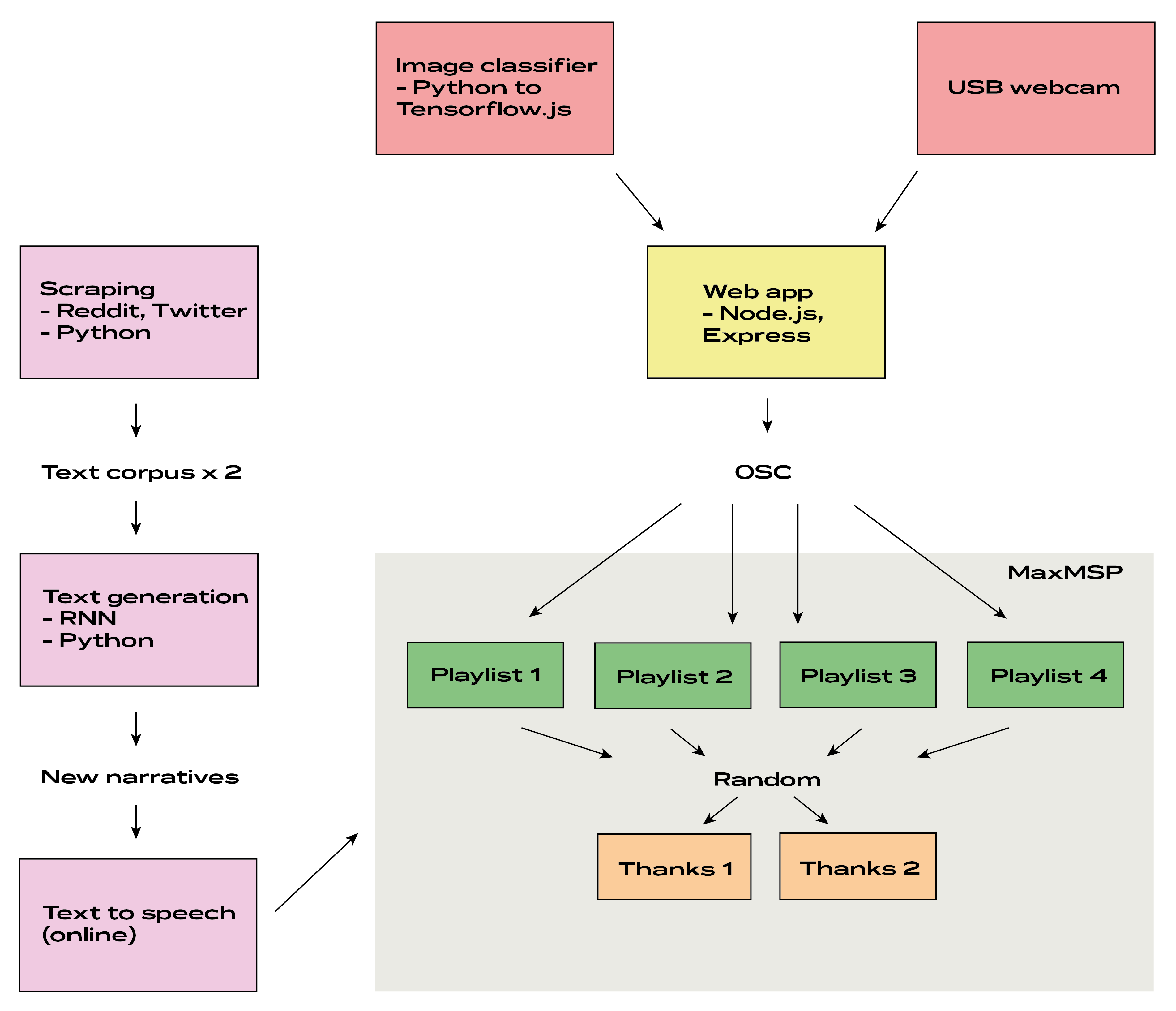
My installation takes machine learning process to a physical space. The core of the museum setup is a bookshelf where a chaotic set of images waits to be classified. Exposed on the wall is the dataset, 200 images, that the classifier has now been trained on. This represents museum’s current knowledge. By seeing this dataset, the audience is able to assess and predict the classification decisions and test the limits of the system. Furthermore, on the desk next to the bookshelf is a monitor that shows the museum’s web app. The same web app drives the installation and provides background information for the visitors.
Dataset. I chose to build an image classifier from 200 open access images from Unsplash. With transfer learning, this amount was enough for building a well-functioning model. I chose to have two classes for abstract monsters and, thus, downloaded 50 images tagged with virus and 50 tagged with surveillance. I named these classes into danger and threat, to allow for more ambiguous audience classifications later. To make things more interesting, I downloaded 50 images tagged with security. These images of CCTVs and mobile phones were very similar to ones tagged with surveillance, creating a tension within my dataset. Finally, I chose 50 images with disposable gloves to represent class human. Apart from being a safety measure in Covid-19 circumstances, gloves became a part of the interaction – as machine learning model recognizes them every now and then, the user and the archive form an active, vibrant relationship that Bruno (2016) writes about. Like in digital-only machine learning, this archive has hundreds of test images that are not yet classified. Users interact by putting these images under the USB camera instrument on the bookshelf.
Classification model. The image classifier is built with a Python script retrain.py by Tensorflow authors. By using terminal commands, I trained a custom model on top of Mobilenet feature vectors. Only the top layers of the Mobilenet model are retrained, resulting in an accurate model for my custom classes. I tried many notebook alternatives for this command-line approach, ranging from building a Keras image classifier from scratch and training a transfer learning model in Keras. However, despite getting an accurate model in Python environment I struggled with making the same model perform well after converting it to Tensorflow.js and applying it to the webcam feed. Most of the online resources focus on ready-made Tensorflow.js models instead of custom ones. Finally the solution was to retrain the Mobilenet model in terminal with retrain.py, convert the result to Tensorflow.js with their command line tool and apply certain image preprocessing operations to webcam frames in my web app.








Web app. Museum’s website is a local Node.js app using an Express server. For this installation, local app was a fitting choice as it allowed seamless OSC communication with MaxMSP and was aimed at people physically visiting the exhibition. Central to the web app are broadcast.js and watch.js, where I have followed Gabriel Tanners (no date) tutorial on peer-to-peer WebRTC broadcasting. Broadcast.js shows webcam feed from the USB camera. Under that feed, my Tensorflow.js model classifies the webcam frames. Using my custom function, broadcast.js runs the prediction loop every two seconds. When it recognizes a new class in the frame (danger changes to threat etc.), it sends a respective OSC message via server.js to MaxMSP.
Watch.js is a replicate of broadcast.js, except that it does not send OSC messages. Its webcam feed is streamed from broadcast.js. It is watch.js that is open for the audience to explore on the monitor at the installation. Broadcast.js runs on my hidden laptop and directs the installation. This means that the audience can freely explore the museum’s website without disrupting the pixel readings. “About” section tells audience about the museum’s mission and “Archive” section shows the dataset. This section will have a more meaningful role if developing the app into an online museum in the future.
I wanted the web app to have a minimal, yet slightly quirky design. Animated logo reflects the temporary nature of the museum by imitating the process of highlighting a text before editing it. Here I used CSS skills that I had learned in a workshop by Rebecca Aston (2020) during our In-grid residency.
MaxMSP. My MaxMSP patch receives OSC messages from the web server as integers between 1-4. Each integer corresponds to a playlist and triggers a random track from it. The track tells what the classification system sees in the webcam and reads a related narrative. (More about narratives in the next section). After the track is read, one of the two thank you messages is triggered. The museum asks the audience to re-classify the current system by putting the image in a labelled box that they find appropriate. This results in a new, collective dataset that gives the museum its iterative nature. There is also an additional delete box that excludes images from the future dataset - quite a powerful act in archiving that I wanted to test.
Scraping and RNN. The museum hints at the tradition of bestiaries by reading aloud contemporary monster stories. I decided that Reddit discussions would form a good corpus for these. Be it anxieties regarding Covid-19 or losing privacy, Reddit threads have become a platform where contemporary monsters are discussed in a vulnerable way. By using two Python scripts, I uploaded dozens of pages of Reddit comments from relevant threads and added some scraped Twitter content to the mix by searching with hashtags like #surveillance, #virus and so on. Using these corpuses of virus and surveillance discussions, I trained two RNN models that generated new monster discussions into text files. From this text mass I hand-picked short sections as my monster narratives. I wanted to emphasize the uncanny nature of these stories by converting them to audio with text-to-speech robots I found online. At this museum, even audio exists at the border, being almost human but revealing its robotic qualities every now and then. Similarly, when the system classifies something as security or human, it reads aloud related categories and thus implies that not all categories of the system are visible.
Future development
Next, I would like to incorpotate liveness in the project. I have already tested a Python script that makes a Google search with a selected query each time a certain classification is made in the web app. However, I decided to leave it for the next version as Google’s server quite often gave an error about too many queries. Making the script search for, say, Covid-19 symptoms and printing the summary of the top results would suit the general concept where we turn to internet forums when dealing with our contemporary monsters.
As another development I could move all the interactions to a publicly available web app. This would detach the app from the physical installation, meaning that the USB webcam feed would be replaced with another type of input. Maybe users would upload test images from their computers or live drawings would be classified instead of photos. Updates to the classification system would also happen online, for example by letting people attach and edit labels to a selection of images and making a script that retrains the model regularly.
All in all, the nature of the project is iterative. During this exhibition weekend, 147 images were classified by the audience. Next I will train the model based on this dataset. I expect the model to be noisy, but it reflects the collective understanding of this particular user group. I see the installation as a platform where I can dive into different kind of machine learning experiments in the future. Maybe the images could present urban locations, and the resulting model would reflect the audience’s relationship to their own living environment.

Self evaluation
I’m happy with the project and my learning journey. Of course I’m already aware of some things that I would do differently next time. For example, besides having printed instructions in place, I could make the instuctions more readily available on my web app as well. Another thing worth considering is that, in the current version, the audio pipeline is reserved while one track is played. Classifications might change quickly, and I wanted the audience to hear the narratives as a whole. However, it would be useful to test how the piece works with classifications changing without a delay. All in all, the project meant a considerable learning curve in interactive machine learning and web app architecture. I was able to build a networked system that was very responsive.
References
Readings:
Bowker, G.C. and Star, S. (1999). Sorting Things Out. Classification and Its Consequences. Cambridge: MIT Press.
Brain, T. (2017). The Environment is not a System. Research Values 2018 [online]. Retrived 26 September 2020 from https://researchvalues2018.wordpress.com/2017/12/20/tega-brain-the-environment-is-not-a-system/
Bruno, G. (2016). Storage Space, 16 November [online]. In e-flux Architecture: Superhumanity. Retrived 28 September 2020 from https://www.e-flux.com/architecture/superhumanity/68650/storage-space/
Davis, H. (2020). Creating Datasets. Blog post on a personal website. Retrived 26 September 2020 from http://www.hannahishere.com/creating-datasets/
Dekker, L. (2017). Salty Bitter Sweet. Final project blog for Goldmiths. Retrived 26 September 2020 from https://compartsblog.doc.gold.ac.uk/index.php/work/salty-bitter-sweet/
Dove, G. and Fayard, A-L. (2020). Monsters, Metaphors, and Machine Learning. CHI '20: Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems. New York: Association for Computing Machinery, p. 1-17. Retrived 26 September 2020 from http://www.grahamdove.com/papers/chi2020monsters.pdf
Haraway, D. (1992). The Promises of Monsters: A Regenerative Politics for Inappropriate/d Others. In L. Grossberg, C. Nelson and P. A. Treichler, ed., Cultural Studies. New York: Routledge, p. 295-337. Retrived 26 September 2020 from http://www.zbi.ee/~kalevi/monsters.html.
Kamin, D. (2017). Mid-Century Visions, Programmed Affinities: The Enduring Challenges of Image Classification. Journal of Visual Culture, Vol 16(3), p. 310–336 [online]. Retrived 28 September 2020 from https://journals-sagepub-com.gold.idm.oclc.org/doi/pdf/10.1177/1470412917739739
Mattern, S. (2020). Words in Space. Teaching resources on a personal website. Retrived 26 September 2020 from https://wordsinspace.net/shannon/teaching/
McQuillan, D. (2017). Data Science as Machinic Neoplatonism. Philosophy & Technology, 31, p. 253–272 [online]. Retrived 26 September 2020 from https://doi.org/10.1007/s13347-017-0273-3
Ridler, A. (2020). Anna Ridler [online]. Artist webpage. Retrived 28 September 2020 from http://annaridler.com/
Schmieg, S. (2016). Decision Space [online]. Intervention and website. Retrieved 28 September 2020 from http://sebastianschmieg.com/decision-space/
Shoenberger, E. (2020). What does it mean to decolonize a museum?, 18 September [online]. MuseumNext. Retrieved 28 September 2020 from https://www.museumnext.com/article/what-does-it-mean-to-decolonize-a-museum/
Weinstock, J. A. (2017). Invisible Monsters: Vision, Horror, and Contemporary Culture. In A. S. Mittman and P. J. Dendle, ed., The Ashgate Research Companion to Monsters and the Monstrous. London: Routledge, p. 275-289. Retrieved 28 September 2020 from https://www.routledge.com/The-Ashgate-Research-Companion-to-Monsters-and-the-Monstrous/Mittman-Dendle/p/book/9781472418012
Main references for code:
Aresty, A. (2015). Random sound in Max MSP, 4 April [online]. Retrieved 28 September 2020 from https://www.youtube.com/watch?v=UQAeTkuHFK0
Aston, R. (2020). CSS workshop for In-grid participants, 19 May [online].
Hammar, J.J. (2020). socket_to_OSC. Retrieved 28 September 2020 from https://github.com/veitkal/socket_to_OSC
Hammar, J.J. (2020). webUI_for_OF. Retrieved 28 September 2020 from https://github.com/veitkal/webUI_for_OF
Shiffman, D. (2016) 12.1: Introduction to Node - WebSockets and p5.js Tutorial, 13 April [online]. Also episodes 12.2 -12.4 in the video series. Retrieved 28 September 2020 from https://www.youtube.com/watch?v=bjULmG8fqc8, https://www.youtube.com/watch?v=2hhEOGXcCvg, https://www.youtube.com/watch?v=HZWmrt3Jy10 and https://www.youtube.com/watch?v=i6eP1Lw4gZk
Tanner, G. (no date). Building a WebRTC video broadcast using Javascript [online]. Retrieved 28 September 2020 from https://gabrieltanner.org/blog/webrtc-video-broadcast
Tanner, G. (2019). Scraping Reddit data [online], 5 January. Towards Data Science. Retrieved 28 September 2020 from https://towardsdatascience.com/scraping-reddit-data-1c0af3040768
Tensorflow (2020). Tensorflow.js library [online]. Retrieved 28 September 2020 from https://www.tensorflow.org/js
Tensorflow (2020). Text generation with an RNN [online]. Retrieved 28 September 2020 from https://www.tensorflow.org/tutorials/text/text_generation
Tensorflow (2020). tfjs-converter [online]. Retrieved 28 September 2020 from https://github.com/tensorflow/tfjs/tree/master/tfjs-converter
Tensorflow (2015). Retrain.py [online]. Retrieved 28 September 2020 from https://github.com/tensorflow/hub/blob/master/examples/image_retraining/retrain.py
Vickygian (no date). twitter crawler.txt [online]. Retrieved 28 September 2020 from https://gist.github.com/vickyqian/f70e9ab3910c7c290d9d715491cde44c