






























































Linger
A performance/film production based on an interactive soundscape.
produced by: Yuting Zhu
Linger is a performance based on an interactive soundscape, recreating the spatial experience in a "watercave". With both computer vision and microphone input, the performer uses their body and voice to navigate the virtual cave, hearing sounds from near and far, and have their questions answered in the form of recomposed echoes. Through a play of light and shadow, the performer explores a meditative emotional journey within a restrained space.
This project is presented as a 7-minute-long short film (here in the blog is a 3 mins excerpt) with additional choreography and visual editing, in order to showcase the full story of an attempted conversation between the living and the accidentally dead. (If you're insterested, the full video is here.)
Design concept and context
The "watercave" is a metaphor for the "underworld", the world after life. This imagery is inspired from Sarah Rhul's 2003 play Eurydice, where the mythical character, this time driven by the loss-and-found of attachment with her long departed father, trespasses the world of the living and the dead.
This story immediately reminded me of our abiding need since and beyond the Covid 19 pandemic - to memorize, to make peace with, and to seek consolation from our deceased loved ones. Now, more than ever, people in seclusion earnestly want to reach out for connections and solace to deal with loss. It occurred to me how we used to stand in front of a gravestone or hold a photograph in hand, and start talking to an imaginary soul - "which job should I take?"; "are the kids gonna be alright?" - sometimes claiming we can hear the answers in our heart while aware that they're only the echoes of our own voice.
Hence the "watercave": an enclosed space infused with echoes, signifying both solitude and consolation. One drifts along the stream within to follow the lead of our yearning: just a little closer.
Technical implementation
The project is made with a collaboration between Openframeworks and Max/msp. Max/msp is what takes care of the sound effects, while computer vision input via Openframeworks makes the interaction possible. For the OF part, the technical challenge mainly rests on two things: a spatial experience and motion detection.
Right in the beginning I knew I wanted an interaction to simulate the image of a traveller trying to explore a place in darkness, holding a torchlight. To make this movement convincing and engaging, I needed the soundscape to sound different depending on where the traveller is "looking at".
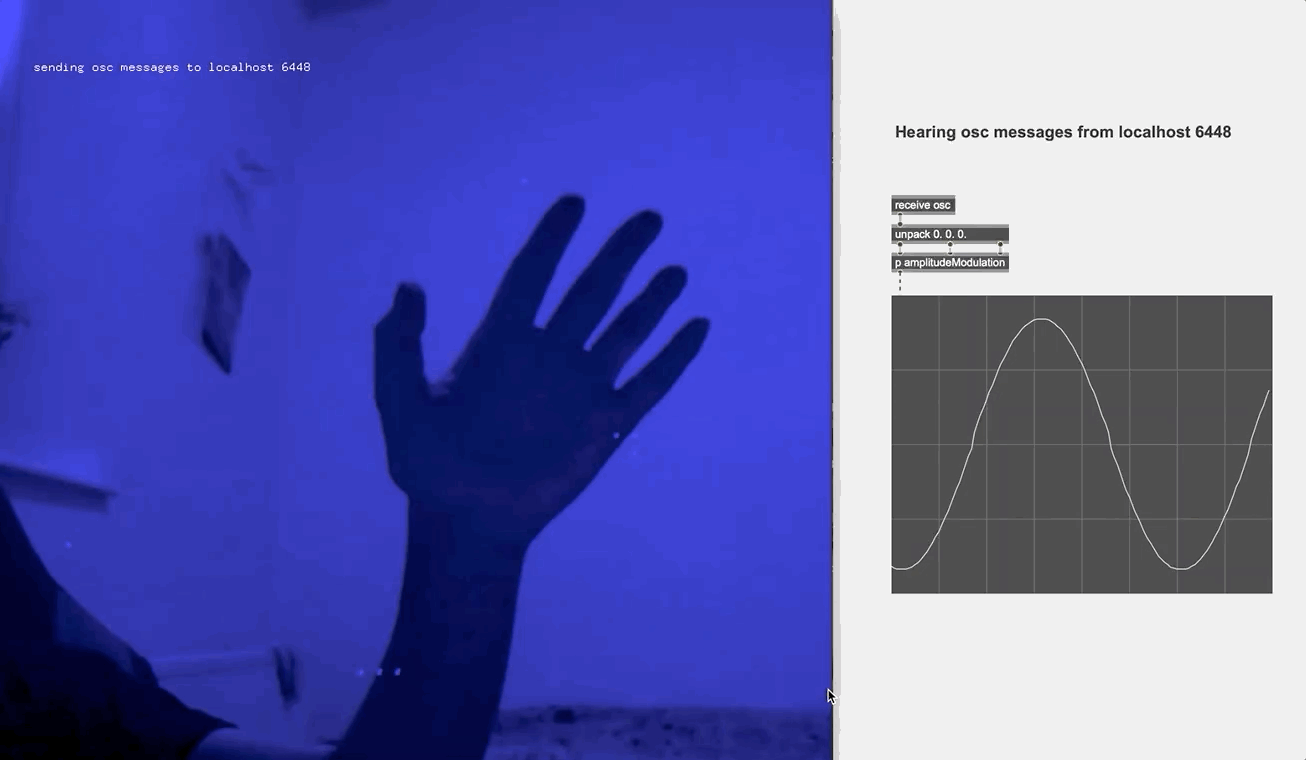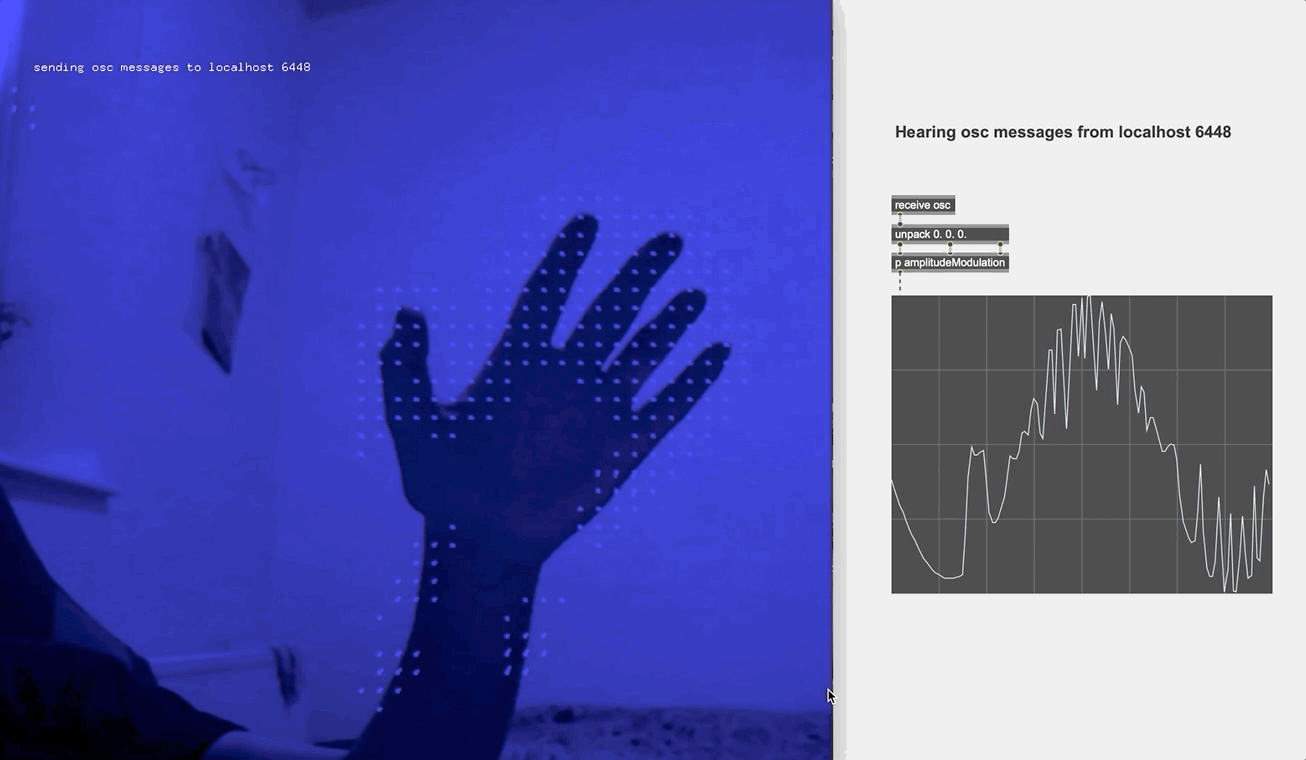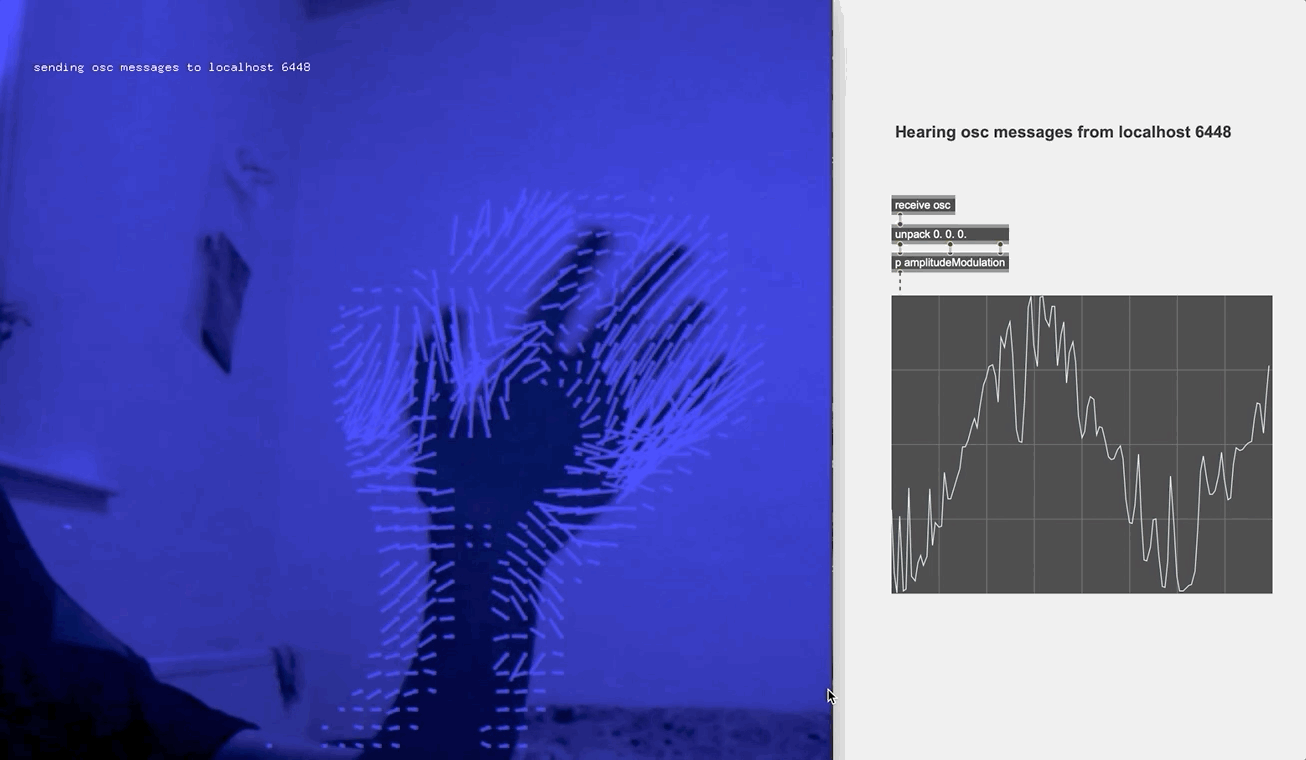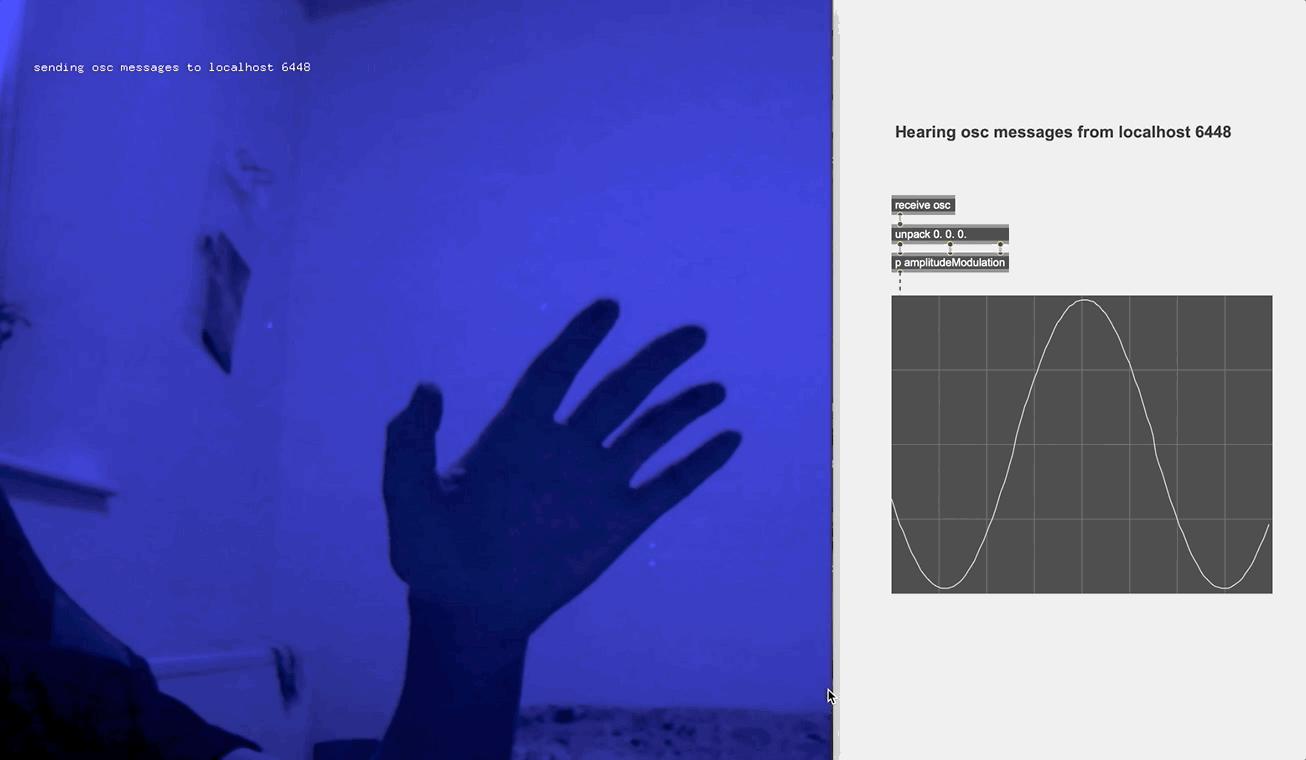
A handy tool in Max/msp inspired me (see picture below): the node object allowed me to overlay different sound combos on the "map", and proportionally adjust the volumes of each combo depending on their distance to the moving pointer, as if someone is walking from one sound source to a another in a virtual space. Then what I needed was a clean and controllable pointer to nagivate the map with. Computer vision does this job perfectly: I used an Openframeworks application that detects the brightest spot in the webcam image (which is where the mini torch is held), and then sends the precise coordinates to the Max patcher via osc messages.

After finishing with the torchlight part, I felt that although such a highly calibrated interation guarantees the intended effect, it is somewhat limiting for a performance. I wanted to allow the performer's body movements to interfere with the sound they hear with a bit more freedom and unpredictability.
So I looked to the optical flow technique for motion detection. The original idea was when the performer waves their hand in the upper left, upper right, lower left and lower right corner of the screen, different effect parameters are modified in each of the case. Yet soon enough I found it would easily escalate into a maximalist chaos. So I toned it down, using only the "direction" and "intensity" values and just for manipulating the microphone parameters for a clean and stand-out effect. I also embedded the webcam video on the screen when the performance took place, in order to spotlight the live manipulation for the audience.
Visual editing and future development
All the above combined, what you see is me as the performer facing the gleaming laptop screen in a dark corner, using lights, gestures, sound-making objects, as well as voice to compose a score live. Looking back at the scratch performance, I couldn't tell for sure if the performer was the musician or the character or somewhere in between. Thus when extending it into a short film, I applied a visual language to highlight this dual identity of the performer, where "the musician" and "the character" are layered onto each other like ghosts.
For further development, I'd love to explore customized performance. One-on-one in the same dark place, but where the audience can navigate and manipulate the soundscape themselves. The soundscape could perhaps also incorporate the sounds in their life (pre-recorded at home or live) to render a much more personal experience.
Code References
[1] Theo Papatheodorou's code examples from Week 12&13: Computer Vision Part I. & II.
[2] Theo Papatheodorou's code examples from Week 15: OSC Messaging