






























































Computing my Markings
A study on digital cloning and data quantification.
This project arose almost a year and a half ago when I was still working as a Creative Technologist at interactive agency Happy Finish. We started investigating data cloning as a possible topic for our pitch for SXSW festival. This is where the initial idea of analyzing and quantifying a real human’s data came to mind. Alongside my then manager Marco Marchesi and the rest of the HF team, we have spent the last six months gathering and analyzing the data of a volunteer subject: myself.
Even though we successfully got chosen as speakers for the festival, it, unfortunately, got canceled due to Covid-19. Nevertheless, we are still working on newer iterations of the clone and will be very excited to officially release the final version next year. In the meantime, I have used this opportunity as a reflection of my first-hand experience downloading, curating and processing my own personal data for digital cloning. The essay will show my process of analysis of what it means to have a personality, its traits and how we can approach the quantification of personal data. Finally, I also include a personal interpretation of my data using RunwayML as an artifact and reflection of my findings.
By: Alesandra Miro Quesada

Introduction
When thinking on the subject of digital cloning, an array of fascinating words arise;
Transhumanism Uploading Ethics Orwellian
Data Neural Networks Biotech Singularity
Machine Learning Eternal
AI Computing Power Altered Carbon, you know that Netflix Series
Psychology Cyborg
Digital cloning is a subject that incorporates many disciplines and an array of scientific and psychological schools of thought. One could take a neurological approach and study the synaptic processes that take place in the brain, then switch to computer science and try to recreate this model using Neural Networks (Kurzweil, 2005). From the humanistic point of view one could discuss the desire of eternal life through code, while in popular media, digital cloning has appeared in famous shows such as Altered Carbon, Years & Years and Black Mirror, rendering this a subject common to public consumption.
There are sublime questions to be discussed when it comes to the future of big data and the way machines are computing information. Philosopher, Nick Bostrom, talks about the “AI Control Problem”, where one must train an AI with goals common to our own human survival and well being. More specifically, writer and Journalist, Mark O′Connell, provocatively explores the world of human augmentation in the new Transhumanist Movement. Such investigations about the relationship between humans and AI are nothing new. Ray Kurzweil, world renowned inventor and futurist, has been talking about data cloning since the mid 90s where, among many other fascinating subjects, he describes the complexity of our biological grey matter for the hypothetical creation of a computational model of our brains (Kurzweil, 2005).
As one can see, the subject of digital cloning can be immensely interesting and undoubtedly overwhelming to approach. In order to tackle it, I decided to look closer to home and explore the cloning of multiple human qualities that form an individual's distinctive character. This essay will bring the subject of digital cloning to a current time and explore:
To what extent can one digitally reproduce an individual, based on personal data and the current computing tools available in 2020.
I will aim to explore what it is to have personality; the different aspects of it and how humans inevitably and willingly produce data that could be used computationally for the recreation of that particular individual. I want to focus on the computational side of the process, in terms of what types of Neural Networks are needed and what type of data needs to be collected from that particular individual. I will also look at the age of Dataism (Harari, 2015) and how most websites have tracking systems that analyze and process personal data to sell or use in an array of ways. This data, which more often than not is given willingly by the user is being used as we speak to indulge an insatiable algorithm churning away in the unconfined world of cyberspace.
Put aside your google history, amazon suggestions or youtube recommendations. On facebook alone, an average human produces heaps and heaps of data that points directly to their political views, relationships, ethical stances, interests and more. Enough for a reader to understand them, let alone an efficient algorithm (Luerweg, 2019). Nowadays, Generative Adversarial Networks (GANs) need roughly 500 images of a person's face to learn his or hers particular pixel combinations (Shiffman, 2019). Once this is accomplished the doors are open for an array of digital image manipulation scenarios.
There is no doubt that the age of Deep Learning is here and that one does not need a Computer Science or Maths degree to access it. Even though this essay aims to be somewhat speculative, this freedom inspired me to pursue my own dystopian research into digital cloning and attempt to gather enough data to train and compute an audiovisual representation of myself. The road is bumpy ahead as I brace myself to go over cringe facebook pics, friend’s old messages and explore the sheer extent of data which is needed to calculate and interpret somebody's essence and personality.
Computational Ingredients
When computing a person, one could start in dissecting their character. Like the word suggests, charaktēr from the greek noun, to ‘mark, distinctive quality’ (Merriam-Webster, n.d.) refers to something unique, a unique mark, combination or pattern that distinguishes you from another conglomeration of carbon cells. All of these markings take place in the brain, specifically the neocortex; a corrugated mountain range of grey matter that accounts for 80% of the total mass of the brain.
‘The neocortex recognises everything. From visual objects to abstract concepts, controlling movement, reasoning from spatial orientation to rational thought and language, basically what we regard as thinking’(!!!)(Kurzweil, 2012).
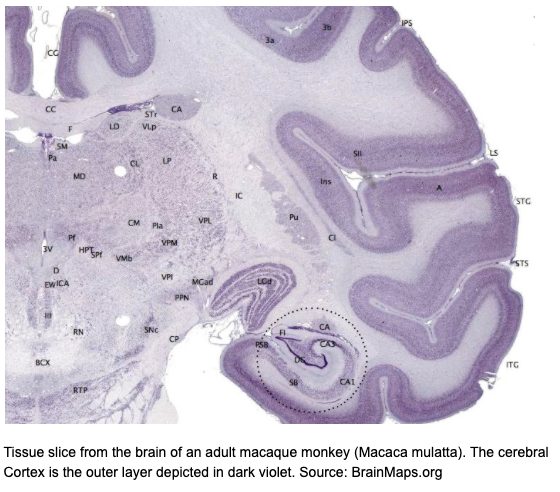
Here lies the essence of self; your unique markings. It is in the reverse engineering of the Neocortex that the field of Computational Neuroscience is advancing towards (Kurzweil, 2012). Furthermore, any of its successes, if paired with the successes in the advances of Artificial Intelligence could potentially lead to one of the greatest systems ever created by humankind.
This technology is, however, a few decades away, so in the meantime we are going to focus on a more current approach in which we could try and capture an individual′s unique markings: what makes them laugh, their political views, favorite films, songs, etc. How can we gather this information without having to clone a neocortex? What is the computational power within our reach right now and what functions and algorithms are needed to create a system that can converse, articulate and give appropriate answers according to a particular individual's data?
In order to tackle digital cloning, it would be useful to separate the different types of data that we are going to need from our subject, person X, in order to try to quantify its data:
First, this system should look like that individual. It should display a distinctive pixel pattern that can be accurately interpreted as person X.
Next this system should sound like that individual. It should create the same sounds, pauses and stutters unique to person X.
More importantly, this system should interpret the data in such an accurate manner that when another individual interacts with person X′s system, it displays the same humour, points of view and overall personality.
And finally, of course, it should pass the Turing Test.
Currently, the advances in Neural Networks have paved the way in which computer scientists are creating and training systemes, especially when it comes to image generation (Quiroga, 2017). Generative Adversarial Networks (GANs, which we will hear more about later,) use huge datasets to generate new synthetic instances of data of virtually anything (Ayyubi, 2019). For example, you can train a system that learns the face of a celebrity such as Emma Wattson, using the dataset of 5,000 images of her face, throughout her life long career.
This dataset would then run through two algorithms: a generator, in charge of creating new synthetic images, and a discriminator, in charge of recognizing whether the image is fake or not. Together they are able to generate excellent results in synthesis of plausible images.
This combination is the key to allowing the system to learn the specific pixel pattern for Emma Wattson and using a further face detection algorithm, it has the ability to superimpose Wattson face on top of other people's facial data. These videos became popularly known as ′deepfakes′ and created ethical controversy when popular celebrities' faces were created in pornographic films (Cole, 2018).
These networks are a strong choice when tackling the audiovisual aspect of digital cloning. In other words, we can train a GAN with the audiovisual dataset of a particular individual. In order to do so, we would need that individual's personal data. Since the average human does not have 1000+ hours of screen time like Emma Wattson, this data will need to be sourced elsewhere. For example, most humans now have an online presence. This means that they have provided the internet with their data, from Whatsapp messages to Facebook pictures and Instagram posts. For example, I have been using the internet since I sent my first email back in 2002. Fast Forward to the present day, that is 17 years of constant data that was handed over to the internet and is probably still there, dormant in the abstract dadaistic cyberworld.
This is 17 years of school pictures, prom nights, ex partners, best friends and family that could be compiled and used to train a system. The approach for audio is fairly similar; we can use audio recordings and videos of person X talking and train a system to mimic the pitches, pauses and laughter of that individual's data. These processes however will amount to nothing if they do not work together to achieve what could be coined as a synthetic personality/ a computed personality. There is no point having a system that looks and sounds like person X, but does not argue, tell jokes or feel the same way about things like person X does. It is here where the biggest challenge lies when computing a personality and this is what we will be focusing on in the next chapter.
OK Computer?
Personality is an aspect of consciousness that we might share with the entire animal kingdom. Personalities have been identified in sea cucumbers, water striders, fish, lizards and new species are frequently added to the list (Weizmann Institute of Science, 2019). Perhaps, one day, certain intelligent machines will also be regarded as having a personality.
In the Metamorphosis by Franz Kafka, Gregor Samsa ‘awoke one morning from uneasy dreams, as he found himself transformed into a gigantic insect’(Kafka, 1915). Although this angst par excellent novel tells the tragic story of an unexpected and unwanted transformation, never for one second does the reader stop thinking that that insect's identity is Gregor Samsa. He still recognises his family, his old job and memories. He identifies as Gregorn Samsa, even though his physical shape is now different. Now, imagine that instead of him waking up as an insect, he wakes up as a supercomputer (Quiroga, 2017). To what extent is the biological barrier a deciding factor in what is a personality? Or is it a sense of perspective?
IBM Project Debater is a fantastic example of how humans are managing to compute eloquent and elegant machines (IBM Project Debater, 2019). In the famous debate with Narish Natarajan, grand finalist in the World Debating Championships, both the human debater and the machine debater had the same amount of time to prepare on a topic that neither of them had been given access to prior to the debate. IBM Project debater made jokes, used irony and wit just as well and as eloquently as Mr. Natarajan. The debate was fierce and entertaining. From an audience point of view, not only was the scenario ‘Star-Trekian’, but you could honestly believe that the IBM project debater had some sort of personality. Even though the way in which it processed information was fundamentally different to how a human brain would compute; in the audience's eyes it performed pseudo-human-like, and even phrased its answers in a way that entertained the public. It had a character unique to itself.
This brings us to an interesting crossroads. Even if a personality is computed, do humans need to ‘fall for it’ in order for it to be acknowledged as such? Is a personality only successfully computed if a human being accepts it or if it passes a personality Turing Test (Turin, 1950)? If so, what aspects would they need to pass? Eloquence, or quality of voice, the ability to use irony or synonyms? So far, there is no official barometer to classify a machine’s ‘personalityness’. However, competitions such as the Loebner Prize, in which participants compete for the computer program that is considered the most human-like (Wakefield, 2019), confirms that artificial personality is something many are attempting, researching and programming for.

One might think that these ideas have taken a slightly dystopian turn. After all, we are discussing the creation of synthetic personality achieved by personal data cloning. This might ring a few Black Mirror alarm bells. However, algorithms are already collecting and processing our digital footprints (Luerweg, 2019) and the most interesting part is that most of us are becoming increasingly aware of this (Lewis, 2018). This data collector is embedded in almost every website and although the GDPR (General Data Protection Regulation) came into effect in 2018, companies still find a way to pressure the user into accepting to forfeit their cookies. They know that no one has the time or the inclination to read through terms and click accept for every website and “they are betting that most of us will choose convenience over data protection” (Hill, 2012).
Although it’s fascinating to entertain the idea of a perfectly computed chirpy character in a machine, there are just so many elements that concur on making a “personality” that I think are decades away. We can mimic lapses of personality now, and people can say “it looks like you” because they recognized that particular way you pause between sentences, but that’s it (Marchessi, 2020).
Nevertheless, the Machine Learning (ML) community is steadily advancing towards this goal, as well as many other groundbreaking milestones in the fields of Robotics, Natural Language Processing and Computer Vision. The ML comunity is a big one and now more than ever, people from diverse backgrounds are having access to datasets, algorithms and online documentation. This cybernetical cauldron allows artists, philosophers and enthusiasts to digest the necessary information and learn about these systems to explore and challenge them.
The Clone
There are currently an array of different Neural Networks (NNs) that are capable of performing extraordinary tasks (Tch, 2017). Generative Adversarial Networks (GANs) can reproduce, generate, copy and manipulate visual data while Convolutional Neural Networks (CNNs) thrive in image recognition and classification; CNNs are consequently the NN used in creating the infamous ‘deepfakes’. In text generation, Recurrent Neural Networks (RNNs) have the ability to learn text style and produce eloquent paragraphs.These are only a few Neural Networks in the vastly exciting world of Machine Learning; all of the potential candidates to explore data cloning. For this essay, I will attempt to quantify the visual data of a subject based on their social media and mobile phone data.
I will separate my approach in two parts: dataset gathering and machine learning training. I want to make clear that this artifact will be exploring the computational and technical side of data cloning rather than the psychological and humanistic side of what it means to be digitally cloned. I want to treat and analyse my data as data alone, and not label it with a name, gender or any other characteristic; the NN will take care of that.
I will be using Runway, an interface based ML software that allows artists and creators to train and work with a growing number of NN models. I have three NNs in mind that will help me with the interpretation of my personal dataset: StyleGAN-2 for image generation, GPT-2 for text processing and First-Order-Motion-Model for the potential animation and interpretation of personality.
Now, into creating the dataset. From Facebook and Whatsapp I downloaded: pictures (2009 - 2017) and chat history (2009 - 2017), then went onto Google Photos (2016 - 2019) and iCloud (2019 - 2020) and finally phone backups (2014 - 2020). In total I curated and processed 2233 images, roughly 4GB of my facial data and 4502 text files. This process, as exciting as it was, quickly became a painstakingly slow and monotonous task. As my colleague and former manager Dr Marco Merchessi explains, ‘there is a lot to be done with data, before starting any training. Also, data by nature is not really well structured’ (Marchessi, 2020).
Once images were downloaded, they were cropped to just include the individual's face, uploaded onto Runway as an image dataset and trained with the styleGAN-2 model. So what is going to happen with this data? As briefly explained in the Computational Ingredients chapter, the generator will take care of creating new synthetic images, and the discriminator will assess whether these images are Alesandra or not. The aim of the training is to fool the discriminator; the lower the discriminator number, the better model one will have.
The results of the first hours of training were monstrous. I fell out of my chair in laughter as I looked through the first exports of what appears to be splodges and deformed reconstructions of what a NN thinks I look like! As much as I try, it's very hard not to take it personally. During the next couple of hours the system slowly started to improve and a familiar face started to appear. Towards the sixth hour of training I was happy with the results and ready to bring them to liffe.
At this point I knew that the GPT-2 text analysis was going to be very hard to accomplish in the remaining time, so I decided to move onto the animation and quantification of the visual data I had just generated. Using a First-Order-Motion-Model, I was able to animate the previously generated face by using a video recording of my own face reading this very essay. This way, the image will be driven by the video and thus replicate facial movement as well as head tracking with accurate voice data. Even though this is a quick hack in comparison to an in depth text and voice analysis. It again goes to show how far technology has come and how, with a simple video I am able to manipulate and control almost anybody's face.






Conclusion
Diving into the subject of data cloning has opened my eyes to an almost science fiction type practice, where one can explore what it means to be human through the quantification of data. This ever expanding almost abstract medium that is data, has driven technological advances almost exponentially (Harri, 2015) and is responsible for many of the modern economical, political and ethical developments, both good and bad (Harri, 2015).
When cloning somebody's data, the tremendous feat quickly became apparent. Even though the image training results were very impressive, computing a personality is still a few decades away. I wish I would have had more time to work on the social media text quantification as this is where the major insight into the personality is going to be. In the future, I really want to process the text files through a GPT-2 network and then use voice synthesis to generate synthetic audio.
I am looking forward to the development of this project and to further explore digital cloning. I really want to move forward into the text realm and look at generative language based modeling. I am also excited and nervous to keep on training this AI, discovering how it processes and quantifies the data it is given. Hopefully this will be the first essay of many as I further explore the computational process of quantifying an individual’s data.
Bibliography
Cole, S., 2018. People Are Using AI to Create Fake Porn of Their Friends and Classmates. Vice. URL https://www.vice.com/en_us/article/ev5eba/ai-fake-porn-of-friends-deepfakes (accessed 4.22.20).
Harari, Y.N., 2015. Homo Deus, 1st ed. Harvill Secker.
Hill, K., 2012. How Target Figured Out A Teen Girl Was Pregnant Before Her Father Did. Forbes.https://www.forbes.com/sites/kashmirhill/2012/02/16/how-target-figured-out-a-teen-girl-was-pregnant-before-her-father-did/ (accessed 4.22.20).
IBM Project Debater, 2019.
Kafka, F., 1915. The Metamorphosis.
Kurzweil, R., 2012. How to Create a Mind: The Secret of Human Thought Revealed.
Lewis, P., 2018. “Utterly horrifying”: ex-Facebook insider says covert data harvesting was routine. The Guardian.
Luerweg, F., 2019. The Internet Knows You Better Than Your Spouse Does [WWW Document]. Sci. Am. URL https://www.scientificamerican.com/article/the-internet-knows-you-better-than-your-spouse-does/ (accessed 4.22.20).
Marchessi, M., 2020. Interview - Dr Marco Marchesi CTO HappyFinish.
Merriam-Webster, n.d. The Word History and Definition of “Character” | Merriam-Webster https://www.merriam-webster.com/words-at-play/word-history-of-character-origins (accessed 3.21.20).
Shiffman, D., 2019. Introduction to Runway: Machine Learning for Creators (Part 1).
Tch, A., 2017. The mostly complete chart of Neural Networks, explained [WWW Document]. Medium. URL https://towardsdatascience.com/the-mostly-complete-chart-of-neural-networks-explained-3fb6f2367464 (accessed 3.13.20).
Turin, A., 1950. Maquinaria computacional e Inteligencia.
Wakefield, J., 2019. The hobbyists competing to make AI human. BBC News.
Weizmann Institute of Science, 2019. For the first time: A method for measuring animal personality. ScienceDaily.