






























































One Minute Human
How much can a machine learn from one minute of audiovisual data? This installation uses deep voice synthesis and computer vision/face detection with generative adversarial networks to gauge the capabilities of one minute datasets with currently available deep learning techniques. When such easily accessible data becomes capable of synthesizing voices that fools voice-activated devices, will we regard recordings of our own voices–or phone calls–differently?
produced by: Julien Mercier
Introduction
In his 1986 novel One Human Minute, Stanisaw Lem wrote a review for a book that never existed. Analogously, One Minute Human is the prologue to a story that has yet to be written: that of what is private data, and how we become aware of its capabilities. As of 2019, deep fakes’ potential for harm is tangible, and the technology behind them is improving rapidly, transforming what data we consider private faster than we envision.
The starting point of the work was when, right after the end of the second term, Anna Engelhart, a student from the MA Research Architecture reached out the computing department, looking for someone that wanted to collaborate with her on a deep voice synthesizer. At that point in time, my goal was to learn how to use python, tensorflow and pytorch, so I contacted her and we started working together. Her project relates to the utilization of a bridge that connects Ukraine to Crimea in the Russian propaganda, in the context of the Russian annexation of Crimea, in 2014. As part of her research, we are creating a deep fake video of Vladimir Putin, using deep voice synthesis and deep face lab, a technology that makes face mapping seemless through the use of various deep learning networks. As time went, the time I spent on the project as well as my interest for it convinced me to use the techniques I was learning in an installation of my own, for my final project.
Concept and background research
Using deep learning in artworks is relatively new, and I have found that artists tend to stay close to the original intention than the networks' creator usually propose. Among other things, it is rare to see such work being embedded into physical artworks. One of the intention I had with this work was to find ways to put this technology in a physical form, that the public could interact and engage with more. This is how I ended up using bone conducting transducer, which are a kind of speakers that vibrate, but do not transmit the vibrations to a membrane, like traditional speakers do. Instead, you have to physically touch the transducer with your skull (other bones work as well). Your skull vibrates, thus becoming the membrane, and you inner ears pick up the vibrations, creating a weird sensation of sound coming from within. I chose this type of speaker for the conceptual value of “reading Putin’s private thoughts”, but also because it somehow forgives the eneven quality of my audio samples.
One well-known aspect of deep learning is that it gives amazing results when used with huge, high-quality datasets that were gathered and curated for years by entire teams of AI researchers. But often, artists don't have access to the same ressources, which is one of the reasons why working with small, poor-quality dataset is very important. When artists do have access to big production ressources, the trade off is that they are endorsed by important tech companies, making any critique of their doing dubious. The Spectre [fig. 1, below] project by artist Bill Posters is a good example of that. In order to create close-to-perfect deep fake videos, they had to record tens of hours of speech sample with voice actors who came from the same geographical location than their target, as well as shooting with hollywood studio quality conditions, as he explained during a 'de-frag' talk I attended, at Sommerset House this summer. The facebook-owned start-up behind the deep learning is credited alongside his own artworks.
[fig. 1] I wish I Could..., Bill Posters & Daniel Howe, 2019. Part of a series of AI generated 'deep fake' artworks created for the 'Spectre' project. Spectre project on Bill Posters' website
But the most interesting things made with machine learning and deep learning do not come from the traditional art world, right now. The Forensic Architecture group recently published the results of an investigation, that my collaborator participated in, in which they used machine learning to browse through hours of youtube video and reveal the presence of Russian tanks [fig. 2, below] on then-Ukrainian territory, despite Putin's denial of such military occupation. The project, while somehow exagerating the role of machine learning in the overall process, demonstrates a much-needed use for ML in pursuing the facts, rather than the fake. Comissioned by the European Human Rights Advocacy Centre (EHRAC), and submitted as evidence to the European Court of Human Rights, it entails more dimensions that 'traditional' artists are yet to adress when using deep learning technologies.
[fig. 2] The Battle of Ilovaisk: Verifying Russian Military Presence in Eastern Ukraine, The Forensic Architecture Group, 2019. Project's website
The research in small dataset is advancing very fast. Noticably, thanks to results obtained through transfer-learning, which consists in using an existing model (in my case, a succesful text-to-speech synthesizer trained on hundreds of hours of quality data), and continuing to train 'on its shoulders' with any new, small dataset. The new training, with 'dirty data', is likely to damage the existing performances, and requires a particular level of monitoring. I wanted the new model to learn Putin's tone of voice, accent and prosody, but with a little too much training, it unlearnt how to synthesize intelligible sentences in english. After a lot of parameters-tweaking, I could find a balanced result with satisying sounds.
The algorithms used in my work have the particularity of adressing the notion of original vs fake, by tampering with them. They also tend to be better demonstrated with famous figures, because otherwise no one would know whether the fake is good or not. This is what led me to create a narrative around various political figures at first. I trained models on Bin Salmane, Bolsonaro, Maduro, Salvini, Al-Assad, Johhson, Kim Jong Un... [fig. 3, below] Basically, men of power who take issue with journalists, facts, and transparency. However, I realized the multiplication of figures wasn't serving the story I was writing and I decided to keep only Putin's figure.
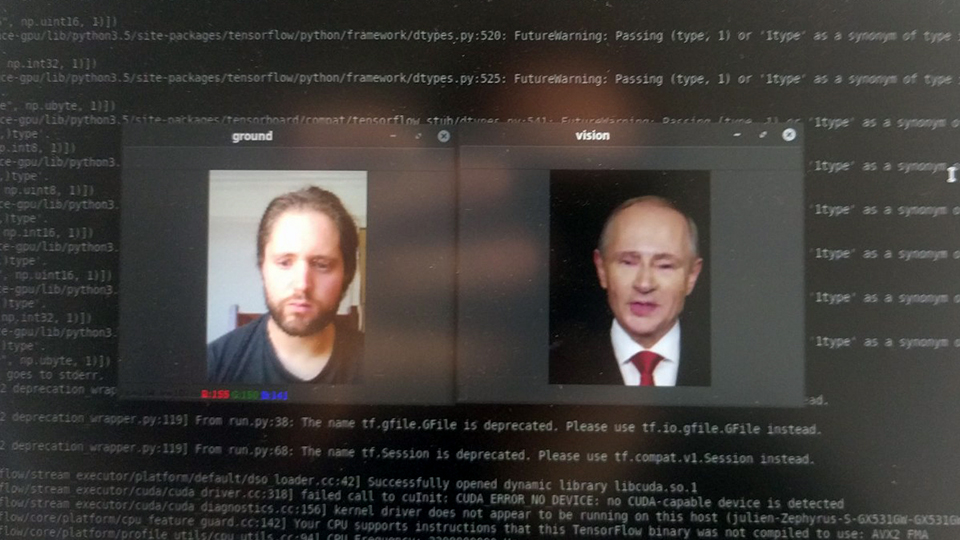
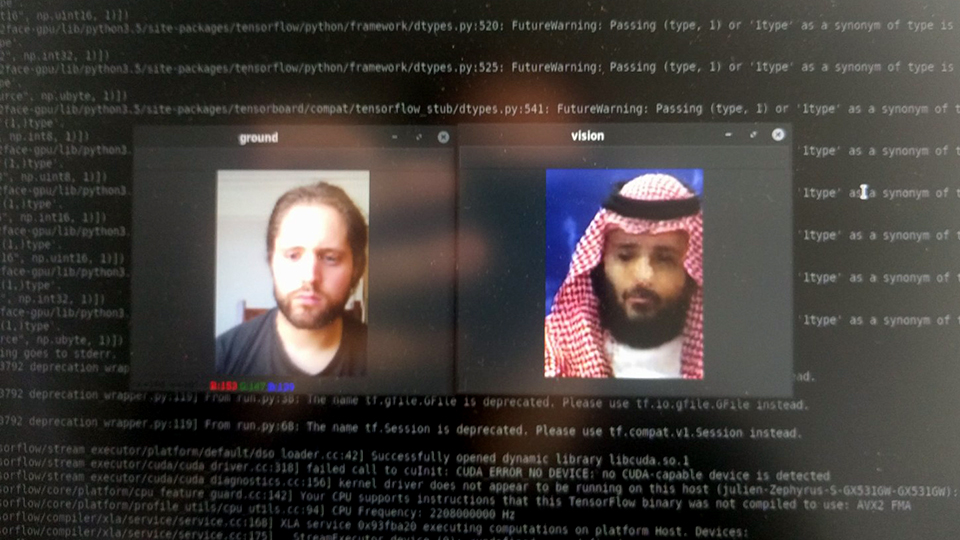
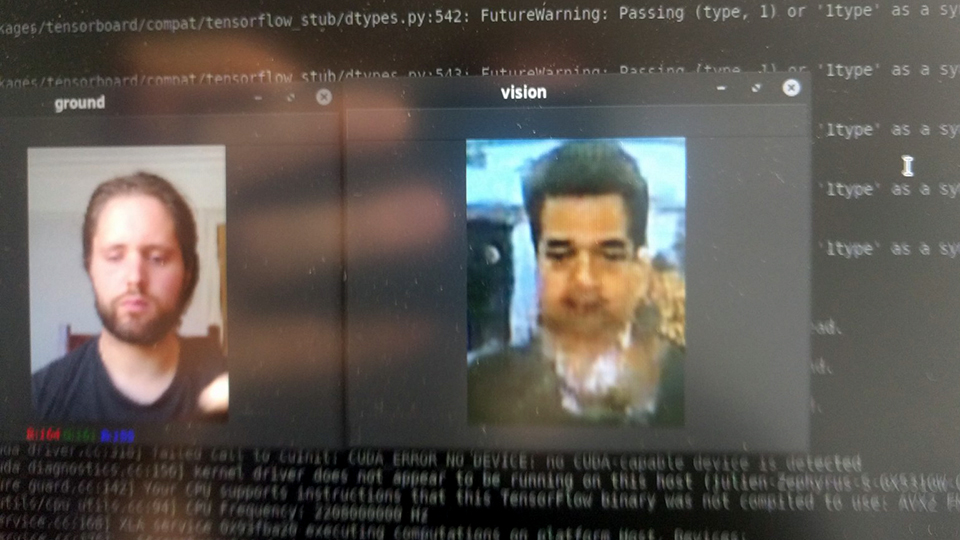

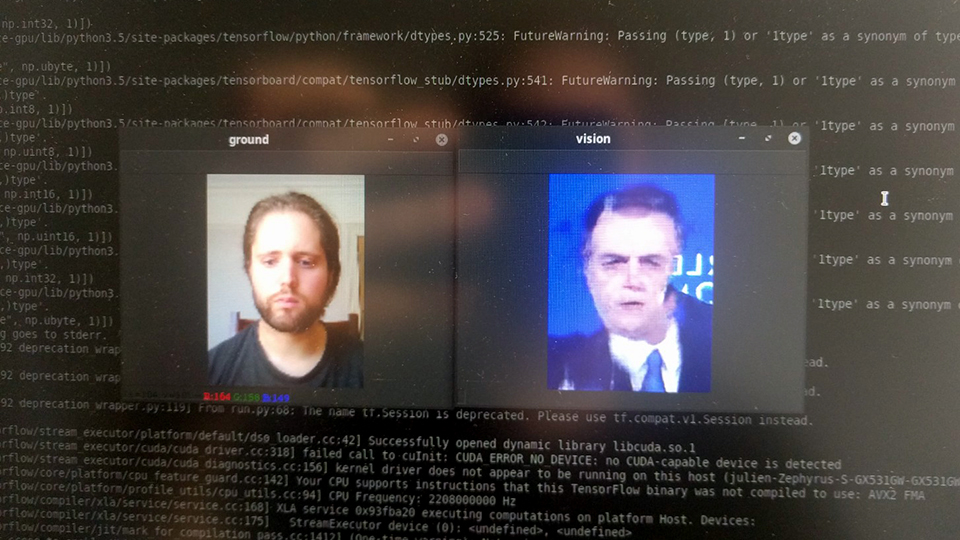
[fig.3] Experimentations on various models, trained from short YouTube videos of speeches or interview, featuring: Prince Khalid bin Salman, Jair Bolsonaro, Boris Johnson, Nicolas Maduro, and Vladimir Putin.
I decided to have fake Putin read parts of a book, rather than narrating any other content, so that it would look and sound like actors auditioning for a part. In this situation, it's a turing test-audition, where the audience gets to decide whether or not his voice sounds convincing. I chose the 1881 novel “The Adventures of Pinocchio” by Carlo Collodi, because it is the story of a puppet (a non-human, who gets manipulated) who lies blatantly, and wants to become a real boy. Put in the mouth of the Russian president, these ideas take a whole new narrative dimension. The real Putin blatantly lies about the Russian occupation in Ukraine prior and after the annexation, despite abundant evidence. The fake Putin in the exhibition is a human-looking, non-human puppet that is being manipulated by its creator author and the audience, and it is passing a turing test, thus “wants” to become a real person.
Technical
After experimenting with mostly supervised learning techniques in Rebecca Fierbink’s course Data and Machine Learning for Artistic Practice in the second term, I wanted to continue and self-teach deep learning techniques. Since most implementations are being done in Python, this was my starting point. I took some introductory online python courses, enough to be able to read and understand the code I needed to use. I also followed a new Kadenze course Creative Applications of Deep Learning with TensorFlow by Parag Mital, a former researcher from Goldsmiths’ Embodied Audio-Visual Interaction Lab.
Since my initial mission was to create a Putin voice synthesizer, I read and experimented with all the available repositories I could find on the topic. The latest advancement are featured in the project deepvoice3, which is based on the previous Wavenet and Tacotron, both created by Google’s DeepMind research group (but implemented and made publicly available by other independant researchers). While I was able to get some interesting result with the Tacotron architecture, it did not handle “dirty data” very well, and training was significantly longer than another architecture that I found: dc-tts. It stands for Deep Convolutional Text-to-Speech networks. Contrary to Tacotron’s recurrent neural network architecture (RNN), dc-tts has a convolutional neural networks architecture (CNN), as hinted by its name. Without the recurring structure of RNNs, it is more straightforward and easy to work with. With high quality data and high-end hardware, it does not perform as well but with the data I used and the hardware I had, it gave much better results, much quicker. Dc-tts turns text into sound waves, and makes them sound like a human voice. While its dataset [fig. 4, below] is parallel (it learns from speech samples, paired with their transcription), it qualifies as “deep learning” because it has multilayer perceptron architecture, or fully connected networks (each cell is connected to all cells in the next layer).
A deep convolutional network takes its name from the fact that two algorithms work a bit like an assembly line: they are like two unskilled workers who don’t know about the other’s skills, but when used in line will produce greater results. The first algorithm it uses is called ‘text2mel’. It takes a text input and learns to make relations between the given text (transcript) and newly created mel spectrograms, which are a kind of numerical representation of a sound signal. The second algorithm is called 'Spectrogram Super-Resolution Network', and it turns the mel spectrogram into a full short-time Fourier transform spectrum, which is able to enhance the resolution (=sound quality) in the scope of a human voice.
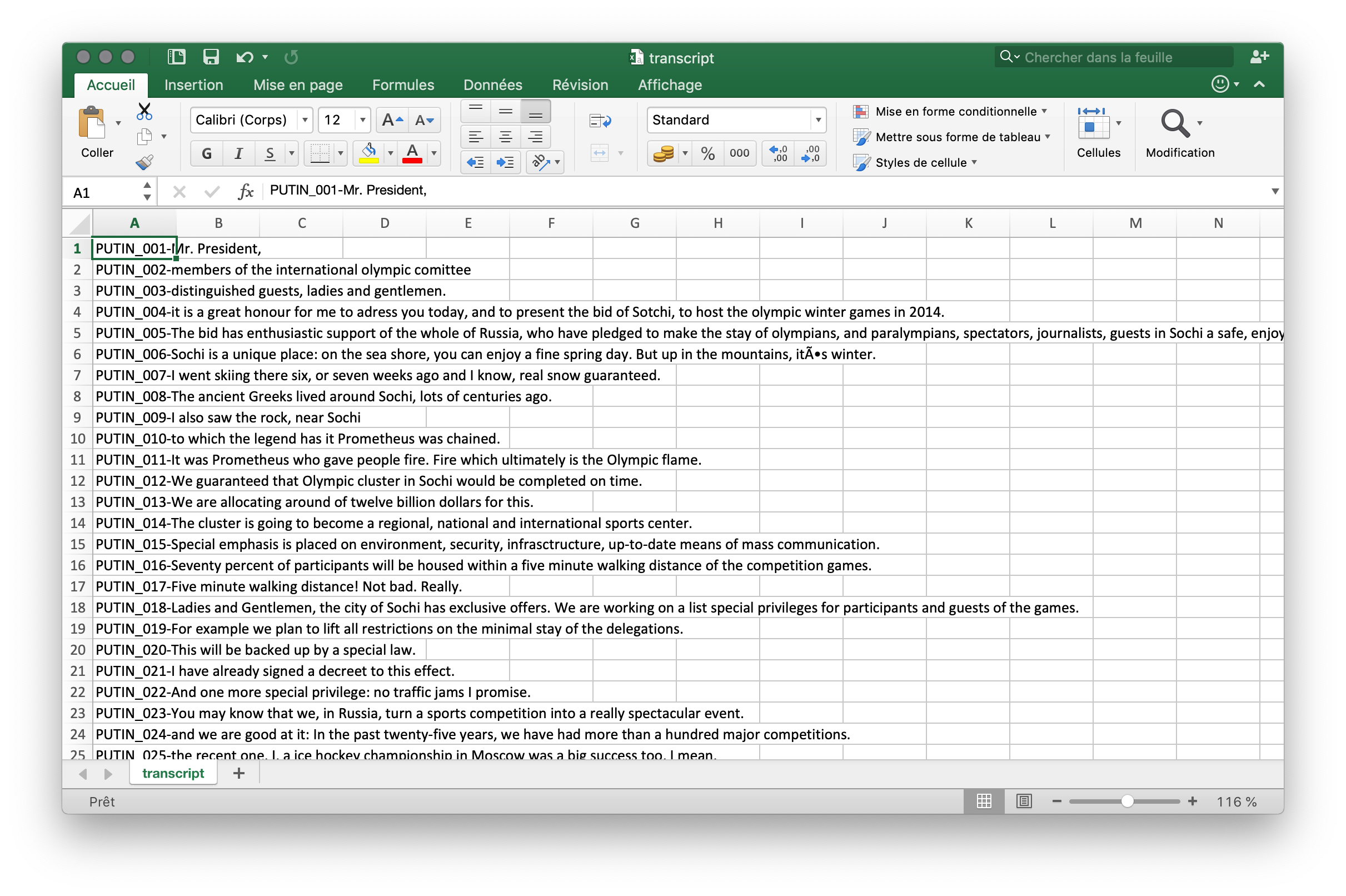
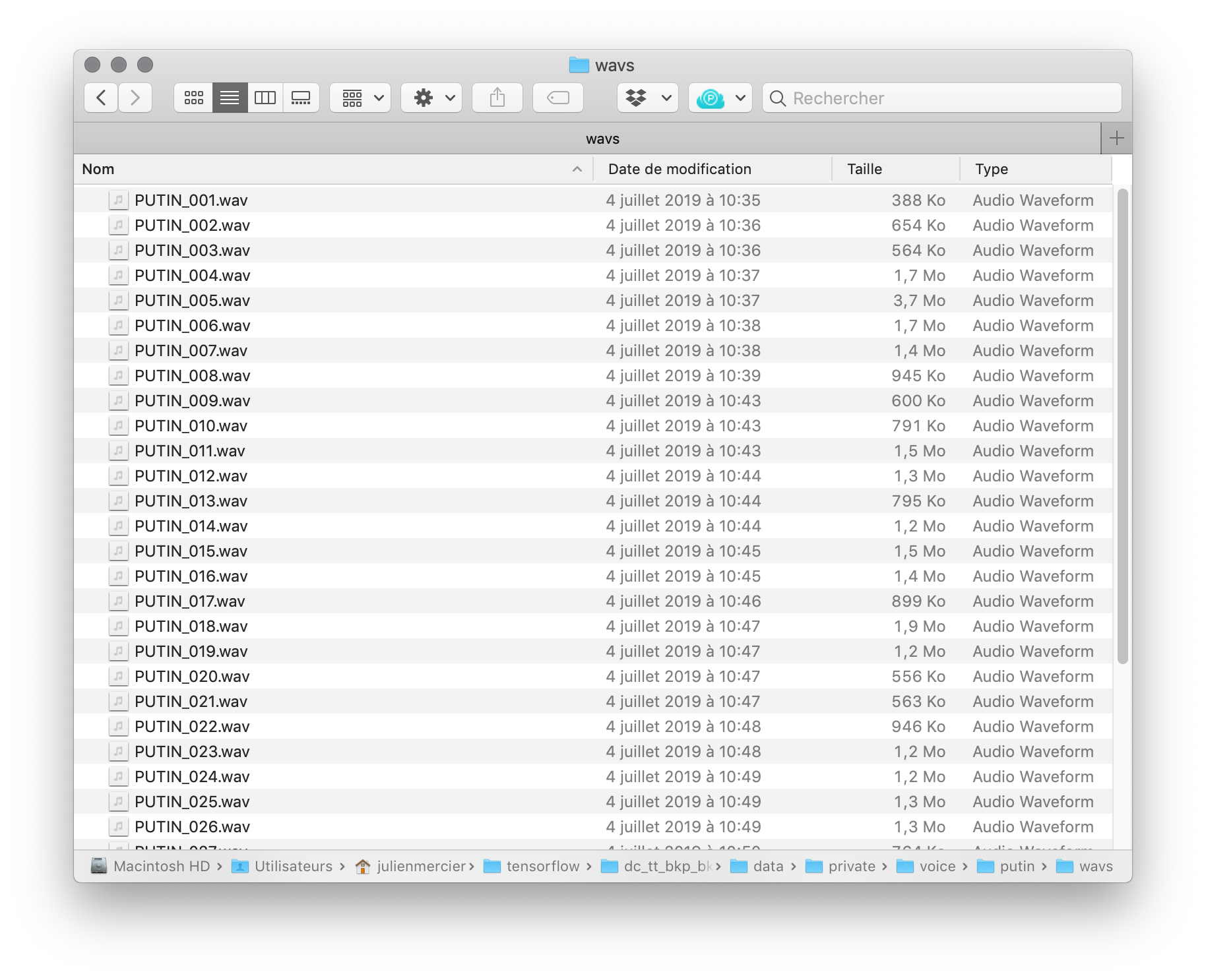
[fig. 4] Preview of the dataset used to train (using transfer learning) dc-tts: segmented samples of Vladimir Putin’s 2007 speech to support Russia’s bid for the 2014 Winter Olympics and their matching transcription in a .csv file.
The second architecture that I used is the famous pix2pix, which also contains two distinct algorithms. Unlike the previous “assembly line” analogy, the two are competing against each other in what's known as a conditional adversarial networks architecture.
Just like with dc-tts, the dataset you feed it with is pairs of images, [fig. 5, below] that presumably contain similarities (such as a collection of images of the same person evidently does). In this case, 24 frames times 60 seconds of Vladimir Putin’s annual adress to the nation, published on the Kremlin’s website. The first step is to create data to pair these frames with. Since I want to “map” these generated pictures to anyone’s face, I used dlib’s face detection API, which is able to draw a mask with nose, eyes and various facial landmarks. In machine learning, this process is equivalent to a reduced, generalized version of the data, that I will furthermore be able to produce from anyone else’s face in the future, give or take.






[fig. 5] Examples extracted from the datasets used to train pix2pix: paired data showing the target (right side), and the facial landmarks (detected by dlib's face detector API) from which to generate it (left side). Later, similar landmark (or source images) will be obtained by running the same face detection algorithm on a live webcam feed.
In pix2pix, the first network (= the generator) will train on these pairs and learn how to generate images that look like the target (right side of the paired data), based on new source data (left side). It will learn to replicate the similarities it has found in the dataset, mostly textures and pixel patterns. The second network (= the discriminator), has trained on the same dataset, but it is only able to tell how close from the training example the new generated content is. It will thus ‘judge’ what the first network has to offer and will grade it. If it does not look realistic, it will discard the image, which will go back in the first network and improve through readjusting the settings (= weights) and give a different result. It will go back and forth like this until the second network deems the image good enough. Again, this is when the power of computation and calculating at the speed of a processing unit that allows this technique to be succesful, because it will have made thousands of attempts within a fraction of a second.
I kept improving the dataset until I had a satisfying, able to generalize and that would work at different scales and positions. Once I had this model, I used code from the TensorRT API to reduce the model. A typical pix2pix model running on a gaming laptop will be able to generate about 1 image per second. But to run (= infer) the model in live like I wanted, the model has to be reduced and then frozen, so that it will keep only the most relevant and useful weights and cells of the network.
After this, a rather simple program [fig. 6, below] is taking a feed from any video source (a webcam in this case) with opencv, running dlib’s face detection algorithm on this source, and running the found landmarks (the mask) in the frozen pix2pix model.
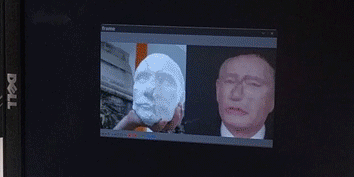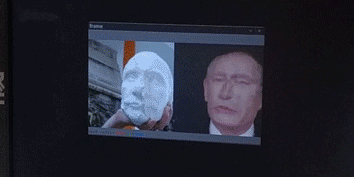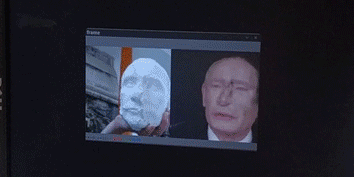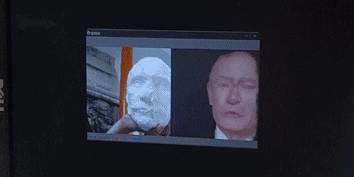
[fig. 6] Demo of live inferrence of the final reduced + frozen pix2pix model, detecting a face on one the early casts with dlib's face recognition API.
The physical computing process [fig. 7, below] behind the installation was pretty simple: I found a freely available 3D model of Putin’s head, made a few changes and adapted it for printing, 3d printed it for 62 hours, pasted it, covered it with clay, spent about 50 hours sanding and carving it to make it look as 'natural' and 'alive' as I could, made a mould, failed to cast it, took it to a professional mould maker, made better casts in sculptamold (a mix of paper and plaster), made holes in the casts, embedded a webcam and some bone conducting transducers in the heads, wired everything to a gaming laptop and an external screen, and wrote a few lines of code to launch the media player (playing the voice samples in the transducer) and to start infering the frozen pix2pix model from the webcam source and display it on the screen.





















[fig. 7] Work-in-progress pictures, from 3D printing to embedding circuits, amplifiers and webcam in Putins’ heads.
Future development
The future developments of this work are very much programmed already, and currently undergoing. They will very soon take a new shape in the MA Research Architecture final show, as part of Anna Engelhart’s final project on the Crimean Annexation. It will feature a fully produced deep fake video using the dc-tts voice model but also brand new models trained with other architecture for face swapping, achieveing much better results (albeit not inferring in live). Together with the same researcher, we have started to pitch a new project involving these techniques in order to find a residency to foster new outputs.
On a general note, I intend to keep on working with deep learning algorithms, with the specific intention to produce tangible, physical, explainable and deconstructing work, that enable the audience to understand what's going on underneath the black box. While I haven’t been able to touch upon the topic of explainable AI and accountability in AI in this post, it is of the utmost importance, as I have tried to explain during the artist talk [fig. 8, below] I gave on friday the 6th of September 2019, during the final show.
One of the early idea of this specific work was to evaluate how 'good' results can be obtained with 1-minute long audiovisual datasets. I will evaluate the opportunity of 'updating' the installation as future implementation of newer algorithms become available, to gauge the improvement in the field of small, crafty datasets.







[fig. 8] Artist talk in the context of the final show, where I tried to discuss and deconstruct the way deep learning algorithm work, in an attempt to unravel the 'black box' they too often represent. Pictures by Ziwei Wu & Nathan Bayliss.
References & Acknowledgements
— Kyubyong Park, for his excellent tensorflow implementation of DC-TTS, and for his various text-to-speech synthesizers implementations (tacotron, deepvoice3, dc-tts...), as well as his work on foreign datasets. The few modifications I have made to Park's original code relate to how to perform transfer learning: training a sucessful model with the standard, massive LJ dataset, then continue training using a different, small dataset (Vladimir Putin speaking in english). This requires a lot of back-and-forth, as the successful model very quickly "unlearns" how to "speak english". Tweaking parameters of the neural net (amount of hidden units, ) mel spectrograms, the batch size, curating the parallel (text == wav file) dataset, and testing every epoch/checkpoint are the critical operations. "Cleaning" the training audio files (noise reduction, silence removal...) has been a key factor. I have tested Park's other implementation of Tacotron2 and though it seems more sophisticated, it is harder to work with small dataset and I could only obtain decent results with dc-tts. Park’s implementation is based on the article Efficiently Trainable Text-to-Speech System Based on Deep Convolutional Networks with Guided Attention, by Tachibana et al.
— Christopher Hesse, for his excellent tensorflow implementation of pix2pix. I have used this repository practically 'as is' without any significant modifications except for environments/local path related variables. The main effort were put in producing quality dataset by preprocessing videos to provide varied data (scale, position) with neutral background. Some model give better results than others, mostly depending on the amount of variation provided in the training samples. Hesse’s implementation is based on the article Image-to-Image Translation with Conditional Adversarial Networks, by Isola et al.
— Dat Tran, for his demonstration of a face-to-face transfer using Hesse’s pix2pix. The main modifications I made on Tran’s code are on the "run.py" file, that runs dlib's shape predictor on a video source and passes it through reduced-and-frozen pix2pix models trained with Hesse's code. I tailored it to the need of my physical setup (monitors, webcam), removed some of the flags and functions and added a function to slide through different models. I have used the other scripts written by Tran (preprocess data, reduce and freeze models) as provided. The process is made abundantly clear on his repository, and I was able to learn a lot from his implementation.
— Parag Mital, for the excellent Kadenze course Creative Applications of Deep Learning with Tensorflow.
— Gene Kogan, for all the educational ressources he makes available on Machine Learning for Artists.
— Memo Akten, for the same reason and his unique philosophical approach to machine learning (read this interview on artnome.com).
— Thanks to my classmates Raphael Theolade, Ankita Anand, Eirini Kalaitzidi, Harry Morley, and George Simms for their help and support. Special thanks to Keita Ikeda for sharing his wisdom on every occasion.
— Anna Engelhart, from the Research Architecture MA, with whom I am collaborating on deep voices and deep fakes.
— Thanks to Theo Papatheodorou, Helen Pritchard, Atau Tanaka, Rebecca Fiebrink, and Lior Ben Gai for their inspirational lectures throughout the year.
— Thanks to Anna Clow, Konstantin Leonenko and Pete Mackenzie for the technical support in the hatchlab.
Technical requirements
— A computer with CUDA enabled (NVIDIA) GPU. Tested on Linux Mint 19.1 with RTX 2070 max-Q design.
— Anaconda 3
for dc-tts
— python == 2.7.16
— tensorflow >= 1.3 (will not work on 1.4)
— numpy >= 1.11.1
— librosa
— tqdm
— matplotlib
— scipy
for pix2pix
— python >= 3.5.0
— tensorflow-gpu == 1.4.1
— numpy == 1.12.0
— protobuf == 3.2.0
— scipy
— OpenCV 3.0 (tested with 4.0)
— Dlib 19.4
Self evaluation
All together, I am very satisfied with how the project turned out. Not necessarily by its technical achievements, but because it took me through a path I wanted to take from the beginning of the year on: I wanted to understand and deep learning techniques, I wanted to learn python, and I wanted to collaborate with someone from Forensic/Research architecture. While these three objectives have not been the only reason I took this path, they justify my satisfaction, looking back at the final project process and the entire MA. I am also very happy at the idea of pursuing the collaboration and being able to refine the way I adress this subject.
Because many of the computation technologies I’ve used are pretty advanced, I haven’t been able to create many of the code I’ve used. Approaching it and understanding how they work alone took most of my current abilities. In the future, I hope that I will get comfortable enough to be able to create my own implementation and deep learning architectures. For now, I have many new implementations to learn from by using them.
I also hope that my future work will fulfill my ambition of covering 'explainable AI' topics, as well as adress the lack of accountability in industrial machine learning nowadays. I hope my future deep learning endeavours will also find new ways to present these techniques, such as by not using the same political/pop figures than everyone else in the field, to begin with.